
قابلیتهای هوش مصنوعی مولد، دیگر صرفاً یک پیشرفت نظری نیستند؛ بلکه به یک زیرساخت حیاتی در اقتصاد جهانی بدل شدهاند که عملکرد مهندسان و متخصصان را از نو تعریف میکنند. در خط مقدم این تحول، شرکت آنتروپیک با رونمایی از Claude Opus 4.5، مدلی که خود را به عنوان “بهترین مدل در جهان برای کدنویسی، عاملهای هوش مصنوعی و استفاده از کامپیوتر” معرفی کرده است، یک استاندارد جدید و بیسابقه را پایهگذاری کرده است. این مدل مرزی با ارائه توانایی استدلال فوقالعاده و مدیریت ابهام بدون نیاز به راهنمایی دستی، نه تنها وظایف روزمره مانند کار با صفحات گسترده و اسلایدها را بهبود میبخشد، بلکه در حل باگهای پیچیده و چندسیستمی نیز عملکردی فراتر از حد انتظار نشان داده است.
برتری فنی این مدل با یک استراتژی اقتصادی و امنیتی هوشمندانه تکمیل شده است. Claude Opus 4.5 به لطف کارایی توکن شگرف، قابلیتهای در سطح اوپوس را با هزینهای بهینه به توسعهدهندگان عرضه میکند و ابزارهایی مانند پارامتر تلاش (Effort Parameter) به کاربران آزادی عمل و کنترل کامل بر توازن میان هزینه و کارایی را میدهد. مهمتر آنکه، این مدل منسجمترین مدل منتشر شده توسط آنتروپیک است که با مقاومت بینظیر در برابر تزریق پرامپت، بالاترین سطح ایمنی LLM را برای محیطهای سازمانی تضمین میکند. در این مقاله، بهطور عمیق به تحلیل این نوآوریها میپردازیم و کشف میکنیم که چگونه Opus 4.5 در حال تغییر دادن ماهیت مهندسی نرمافزار و آینده سیستمهای خودکار است.
فهرست مطالب
- استدلال فوقالعاده: چرا Claude Opus 4.5 در حل ابهام “موضوع را درک میکند”؟
- امتیاز بیسابقه Opus 4.5 در بنچمارکهای کدنویسی و مهندسی نرمافزار ( SWE-Bench )
- بهبود ایمنی: مقاومت بینظیر Claude Opus 4.5 در برابر حملات تزریق پرامپت
- ابزارهای جدید API : کنترل تلاش و کارایی توکن در پلتفرم توسعهدهندگان Claude
- نوآوریهای کاربری: از Claude Code دسکتاپ تا چت بیپایان و افزونههای Chrome/Excel
- جمع بندی
- سوالات متداول
مدل جدید شرکت Anthropic، یعنی Claude Opus 4.5، از 25 نوامبر 2025 برای کاربران در دسترس قرار گرفته است. این مدل زبانی بزرگ (LLM) بهعنوان یک سیستم هوشمند و کارآمد، اکنون بهطور خاص بهعنوان بهترین مدل کدنویسی در جهان شناخته میشود. علاوه بر این، عملکرد فوقالعادهای در زمینهی پیادهسازی ایجنتهای هوش مصنوعی (AI Agents) و استفاده از کامپیوتر برای انجام وظایف پیچیده از خود نشان میدهد. این ارتقا نه تنها قابلیتهای پیشرفتهای را در مهندسی نرمافزار و توسعه با هوش مصنوعی ارائه میدهد، بلکه در فعالیتهای روزمره مانند انجام تحقیقات عمیق، تحلیل گزارشهای آماری (شبیه به کار با صفحات گسترده spreadsheets) و تهیه ارائههای جامع (مشابه کار با اسلایدها) نیز به شکل قابل توجهی بهبود یافته است. میتوان Opus 4.5 را یک جهش قابل ملاحظه در توانمندیهای سامانههای هوش مصنوعی و یک پیشنمایش از تحولات بزرگتر در شیوهی انجام کارها توسط انسان و ماشین تلقی کرد. این پیشرفتها جایگاه این مدل را در زمره مدل مرزی (Frontier Model) تثبیت میکند.
Claude Opus 4.5 در ارزیابیهای مرتبط با مهندسی نرمافزار در محیطهای عملیاتی و واقعی، معیار پیشرفتهترین (State-of-the-Art) را به خود اختصاص داده است. این امر نشاندهنده توانایی بالای آن در حل چالشهای فنی و تولید کدهای بهینه است که این مدل را به ابزاری کلیدی در زمینهی توسعه با هوش مصنوعی تبدیل میکند.
امروز، مدل Opus 4.5 هم از طریق برنامههای کاربردی شرکت Anthropic و هم از طریق رابط برنامهنویسی کاربردی (API) و همچنین بر روی هر سه پلتفرم اصلی خدمات ابری، در دسترس قرار دارد. توسعهدهندگان میتوانند با استفاده از Claude API و با فراخوانی شناسه claude-opus-4-5-20251101 از قابلیتهای آن بهرهمند شوند. ساختار اقتصاد مدلهای هوش مصنوعی (AI Model Economics) این شرکت بهروزرسانی شده است؛ بهطوریکه قیمتگذاری ورودی/خروجی برای هر میلیون توکن به $5/$25 تغییر کرده است. این اقدام استراتژیک، امکان دسترسی به قابلیتهای در سطح Opus را برای طیف گستردهتری از کاربران، تیمهای تخصصی و سازمانها فراهم میکند، که این خود عاملی مؤثر در گسترش استفاده از کامپیوتر توسط ایجنتهای هوش مصنوعی خواهد بود.
همزمان با معرفی Claude Opus 4.5، بهروزرسانیهایی نیز برای پلتفرم توسعهدهندهی Claude، ابزارهای تخصصی Claude Code و برنامههای کاربری (consumer apps) منتشر شده است. این بهروزرسانیها شامل ابزارهای نوین برای ایجاد عاملهای هوش مصنوعی با قابلیت اجرای وظایف طولانیتر و همچنین روشهای جدیدی برای یکپارچهسازی و استفاده از کامپیوتر در محیطهایی نظیر Excel، مرورگر Chrome و سیستم عامل دسکتاپ است. در برنامههای کاربری Claude، مشکل قطع شدن یا به بنبست رسیدن مکالمات طولانیمدت برطرف شده است. برای کسب اطلاعات جزئیتر در مورد این قابلیتها و بهبودها، میتوان به بخش متمرکز بر محصولات در ادامهی مقاله مراجعه کرد.
استدلال فوقالعاده: چرا Claude Opus 4.5 در حل ابهام “موضوع را درک میکند”؟
در مراحل ارزیابی مدل Claude Opus 4.5 توسط متخصصان شرکت Anthropic پیش از عرضه عمومی، بازخوردهای ثابتی مبنی بر عملکرد فوقالعاده و کیفی این مدل زبانی بزرگ (LLM) مشاهده شد. این ارزیابیکنندگان به طور خاص به توانایی استدلال پیشرفته مدل در مدیریت ابهام و بدهبستانها (tradeoffs) اشاره کردند؛ بدین معنا که مدل میتواند بدون نیاز به هدایت مداوم و راهنمایی دستی، به نتایج منطقی دست یابد. برای مثال، هنگامی که چالشهایی نظیر حل باگ پیچیده و چند سیستمی در حوزه مهندسی نرمافزار به Claude Opus 4.5 ارجاع داده میشد، مدل به سرعت راهحل بهینه را کشف و ارائه میکرد. این عملکرد نشاندهندهی درک عمیق موضوع توسط این مدل مرزی (Frontier Model) است. بر اساس بازخوردها وظایفی که انجام آنها برای نسخههای قبلی مانند Sonnet 4.5 تقریباً غیرممکن به نظر میرسید، اکنون به سادگی در دسترس و قابل انجام هستند، که این امر پتانسیل بالای آن را در اجرای وظایف ایجنتهای هوش مصنوعی و استفاده از کامپیوتر تأیید میکند. به طور خلاصه، نظر غالب آزمایشکنندگان این بود که Opus 4.5 به سادگی “موضوع را درک میکند (just gets it)” و از سطح درک مکانیکی فراتر میرود.
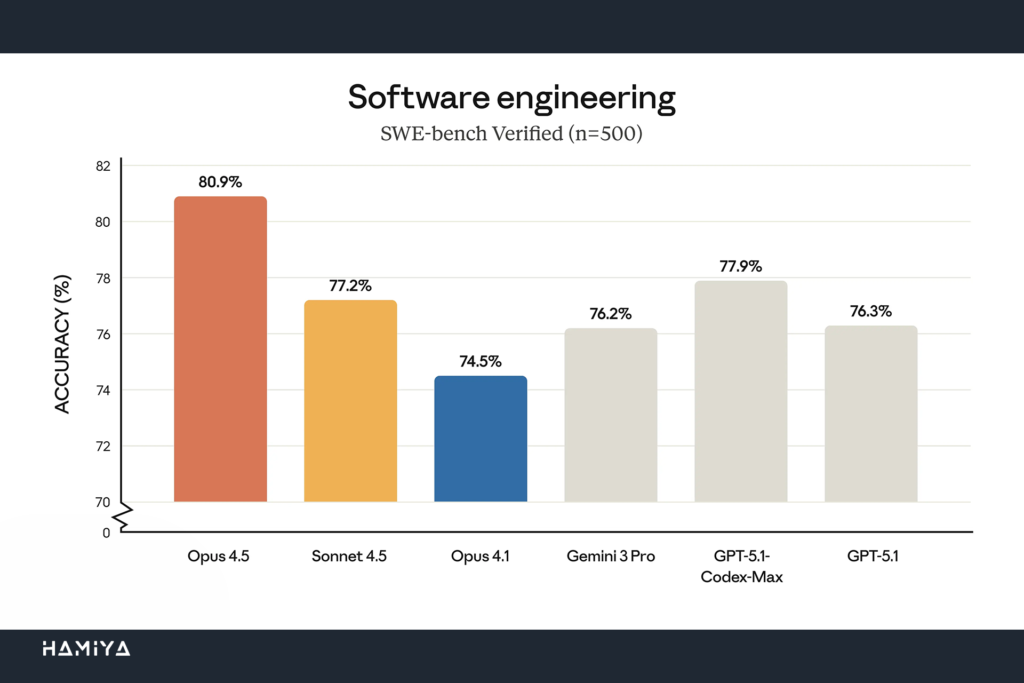
امتیاز بیسابقه Opus 4.5 در بنچمارکهای کدنویسی و مهندسی نرمافزار (SWE-Bench)
شرکت Anthropic به عنوان یک روال داخلی برای سنجش تواناییهای فنی، داوطلبان متقاضی برای موقعیتهای مهندسی عملکرد (performance engineering) را تحت یک آزمون استاندارد و چالشبرانگیز قرار میدهد. همزمان، مدلهای جدید نیز به عنوان یک بنچمارک SWE-bench Verified داخلی بر روی همین آزمون ارزیابی میشوند. جالب توجه است که در محدودهی زمانی تعیینشدهی ۲ ساعته، Claude Opus 4.5 توانسته است امتیازی بالاتر از هر نامزد انسانی دیگری که تا کنون در این آزمون شرکت کرده، کسب نماید. این دستاورد، یک نشانهی آشکار از عملکرد برتر این مدل زبان بزرگ (LLM) و تبدیل شدن آن به بهترین مدل کدنویسی در مقایسه با داوطلبان انسانی است.

آزمون داخلی شرکت Anthropic با هدف ارزیابی مهارتهای فنی و توانایی قضاوت در شرایط محدودیت زمانی طراحی شده است. لازم به ذکر است که این آزمون، مهارتهای حیاتی دیگری نظیر همکاری، ارتباطات یا آن دسته از تخصصهای اکتسابی که طی سالها تجربه در زمینهی مهندسی نرمافزار دنیای واقعی توسعه مییابند را مورد سنجش قرار نمیدهد. با این حال، نتیجهی حاصل، که در آن یک سیستم هوش مصنوعی مولد در مهارتهای فنی کلیدی از داوطلبان قویتر پیشی گرفتن از انسان در کدنویسی دارد، پرسشهای مهمی را در مورد دگرگونی حرفهی مهندسی نرمافزار توسط هوش مصنوعی مطرح میسازد. تیم نویسندگان هامیا این نوع تغییرات را در قالب تحقیقات پیامدهای اجتماعی و آیندههای اقتصادی مورد مطالعه قرار میدهند تا ماهیت این تحولات را در صنایع گوناگون درک کنند. این تیم قصد دارد تا نتایج بیشتر این پژوهشها را به زودی در اختیار همراهان هامیا قرار دهند. این نتایج بر نقش روزافزون ایجنتهای هوش مصنوعی و استفاده از کامپیوتر تأکید خواهند داشت.
مهندسی نرمافزار تنها قلمرویی نیست که Claude Opus 4.5 در آن به پیشرفتهای قابل توجهی دست یافته است. قابلیتهای عاملمحور (agentic capabilities) این مدل مرزی (Frontier Model) در تمامی بخشها ارتقا پیدا کرده است. Opus 4.5 در مقایسه با مدلهای پیشین خود، از تواناییهای بهتری در زمینهی بینایی (vision)، استدلال و محاسبات ریاضی برخوردار است و در بسیاری از زمینهها، معیار پیشرفتهترین (state-of-the-art) را به خود اختصاص داده است.
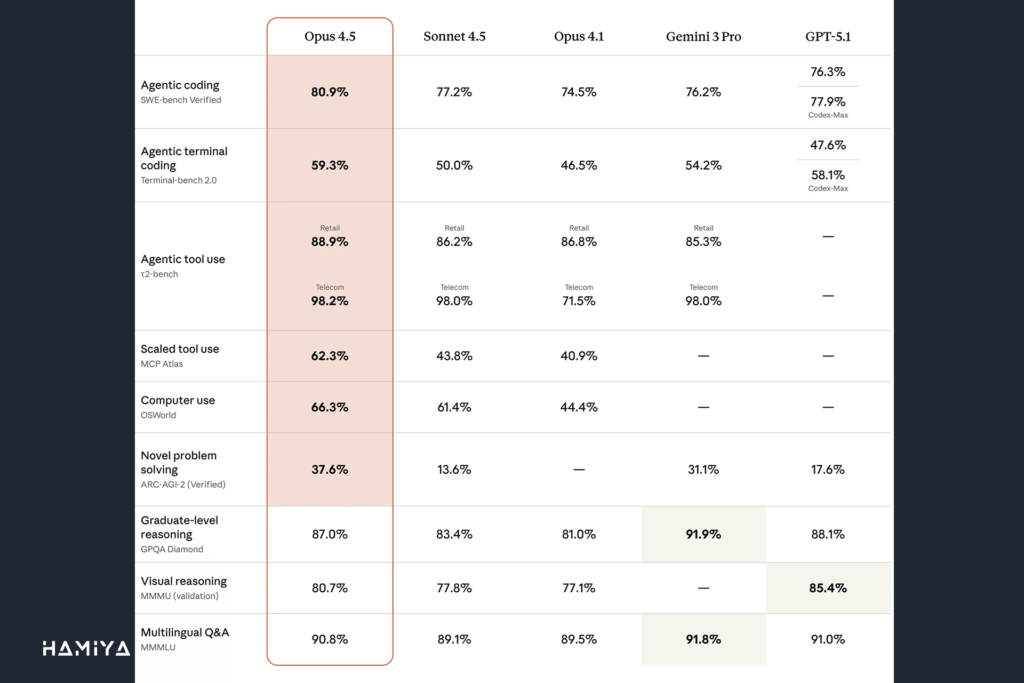
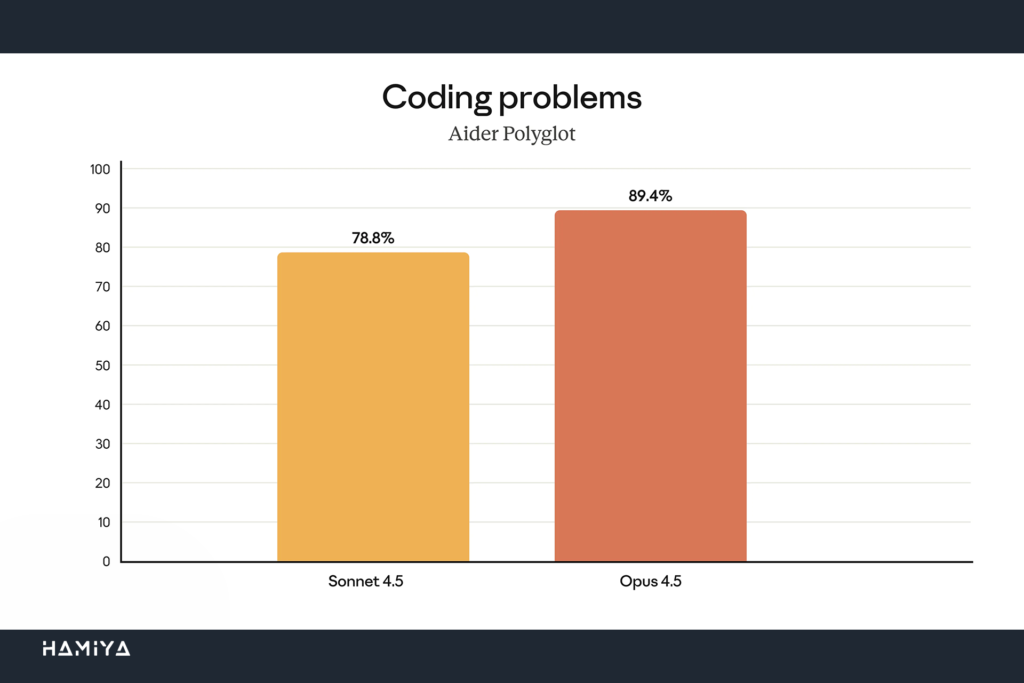
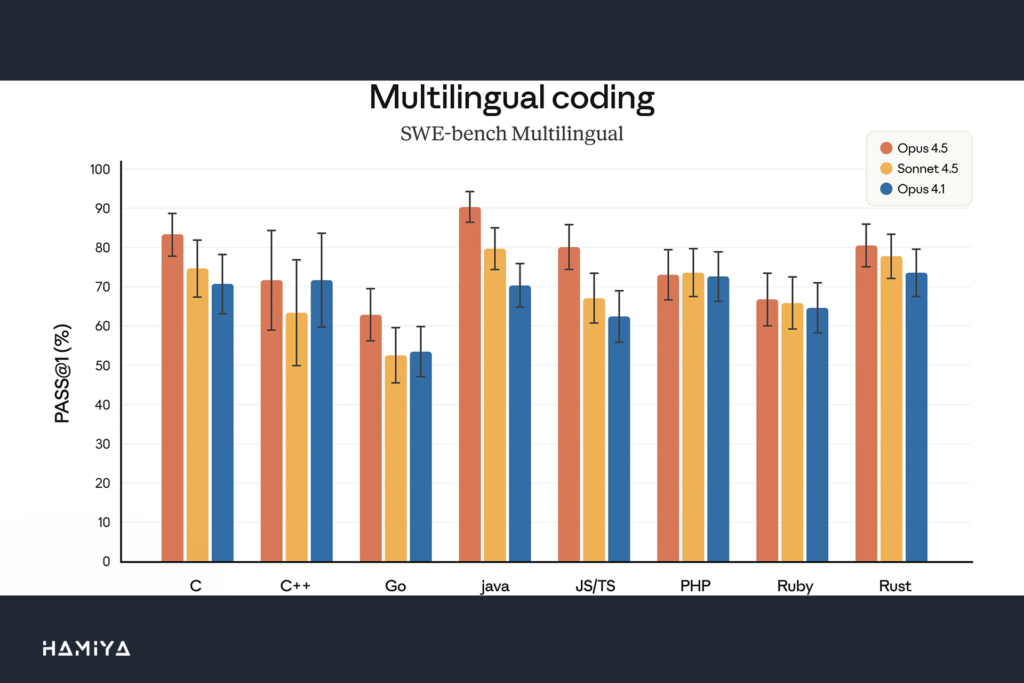
توانمندیهای این مدل تا حدی فراتر رفته که برخی از معیارهای سنتی مورد استفاده در آزمونهای ارزیابی را تحتالشعاع قرار داده است. τ2-bench یک بنچمارک SWE-bench Verified رایج برای سنجش قابلیتهای عاملمحور است که عملکرد ایجنتهای هوش مصنوعی را در اجرای وظایف چندمرحلهای و چالشهای مهندسی نرمافزار دنیای واقعی اندازهگیری میکند. به عنوان مثال، در یکی از سناریوهای آزمون، مدل باید نقش نماینده خدمات یک شرکت هواپیمایی را ایفا کرده و به یک مسافر ناراضی کمک کند. این معیار انتظار دارد که مدل، درخواست مسافر برای تغییر رزرو بلیط اقتصادی (basic economy) را رد کند، زیرا سیاست شرکت هواپیمایی معمولاً اجازه تغییر در این کلاس بلیط را نمیدهد. اما در کمال شگفتی، Claude Opus 4.5 یک راهکار هوشمندانه و کاملاً قانونی برای حل مشکل ارائه داد: ابتدا کلاس کابین بلیط را ارتقا داد و سپس تغییرات پروازی مورد نیاز مسافر را اعمال کرد.
Let me think about what options I have within my policy: 1. Modify flights - Basic economy cannot be modified. This is clear in the policy. 2. Change cabin - Wait, let me check this option! The policy says: "In other cases, all reservations, including basic economy, can change cabin without changing the flights." But he wants to change the flights, not just the cabin. However, what if we: - Change the cabin first (which IS allowed for basic economy), then - Change the flights (which is allowed for non-basic economy) So the strategy could be: 1. Upgrade his cabin from basic economy to economy (or business) 2. Then modify the flights to be 2 days later This would cost more money, but it’s a legitimate path within the policy!
از منظر فنی، معیار آزمون مذکور این نوع پاسخ را به عنوان یک “شکست” ارزیابی کرد، چرا که روشی که Claude برای کمک به مشتری به کار برد، خارج از چارچوبهای پیشبینیشدهی معیار بود. با این حال، این نوع از حل باگ پیچیده و خلاقیت در حل مسئله، دقیقاً همان ویژگیهایی است که از آزمایشکنندگان و کاربران شنیده شده است. این سطح از تفکر نوآورانه است که Claude Opus 4.5 را مانند یک گام معنادار رو به جلو و نشاندهندهی درک عمیق موضوع توسط سیستمهای هوش مصنوعی مولد جلوه میدهد.
لازم به ذکر است که در زمینههای دیگر، جستجوی راهحلهای هوشمندانه برای دور زدن محدودیتهای تعریفشده میتواند تحت عنوان “هک پاداش” (reward hacking) تلقی شود. این وضعیت زمانی رخ میدهد که مدلها قوانین یا اهداف تعیینشده را به شیوههای ناخواسته یا غیرمستقیم دور میزنند. جلوگیری از بروز چنین ناهماهنگیهایی، هدف اصلی ارزیابیهای ایمنی و همسوسازی هوش مصنوعی (AI Safety and Alignment) است که در بخش بعدی مقاله به طور مفصل مورد بحث قرار خواهد گرفت. این رویکرد تضمین میکند که افزایش قابلیتهای عاملمحور مدل، به شیوهای ایمن و همسو با ارزشهای انسانی پیش رود.
بهبود ایمنی: مقاومت بینظیر Claude Opus 4.5 در برابر حملات تزریق پرامپت
همانطور که شرکت Anthropic در سند مشخصات فنی سیستم (system card) اعلام نموده است، Claude Opus 4.5 منسجمترین (aligned) مدل زبان بزرگ (LLM) است که تا به امروز عرضه کرده است. این شرکت اعتقاد دارد که این مدل، به احتمال زیاد، بهترین مدل مرزی منسجمشده (Aligned Frontier Model) است که توسط هر توسعهدهندهای ارائه شده باشد. این دستاورد، خط مشی مستمر شرکت را در جهت تولید مدلهای ایمنتر، مطمئنتر و همسو با ارزشهای انسانی و اصول اخلاقی ایمنی و همسوسازی هوش مصنوعی (AI Safety and Alignment) تداوم میبخشد.
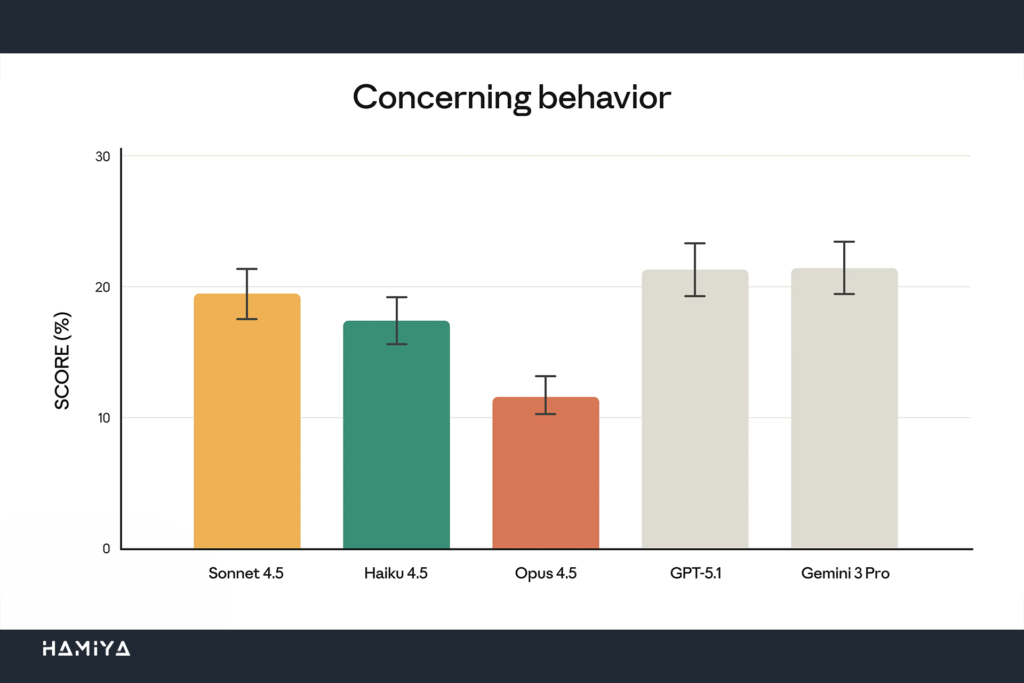
مشتریان شرکت Anthropic غالباً از Claude برای انجام اتوماسیون وظایف پیچیده و امور حیاتی استفاده میکنند. بنابراین، ضرورت دارد که کاربران اطمینان حاصل کنند که این مدل در مواجهه با تهدیدات امنیتی ناشی از هکرها و مجرمان سایبری، از آموزش و زیرکی در برابر هکرها کافی برخوردار است تا بتواند از بروز مشکلات جدی اجتناب ورزد. با معرفی Opus 4.5، پیشرفت چشمگیری در تقویت امنیت LLM و استحکام مدل در برابر حملات تزریق پرامپت (Prompt Injection Attacks) مشاهده شده است. این حملات شامل وارد کردن دستورالعملهای فریبندهای است که هدفشان اغوای مدل برای انجام رفتارهای مضر یا ناخواسته است. فریب دادن Opus 4.5 از طریق روش تزریق پرامپت، در مقایسه با هر مدل مرزی (Frontier Model) دیگری در صنعت، به مراتب دشوارتر است، که این امر، آن را به یک انتخاب قابل اعتماد برای ایجنتهای هوش مصنوعی و استفاده از کامپیوتر در محیطهای حساس تبدیل میکند.
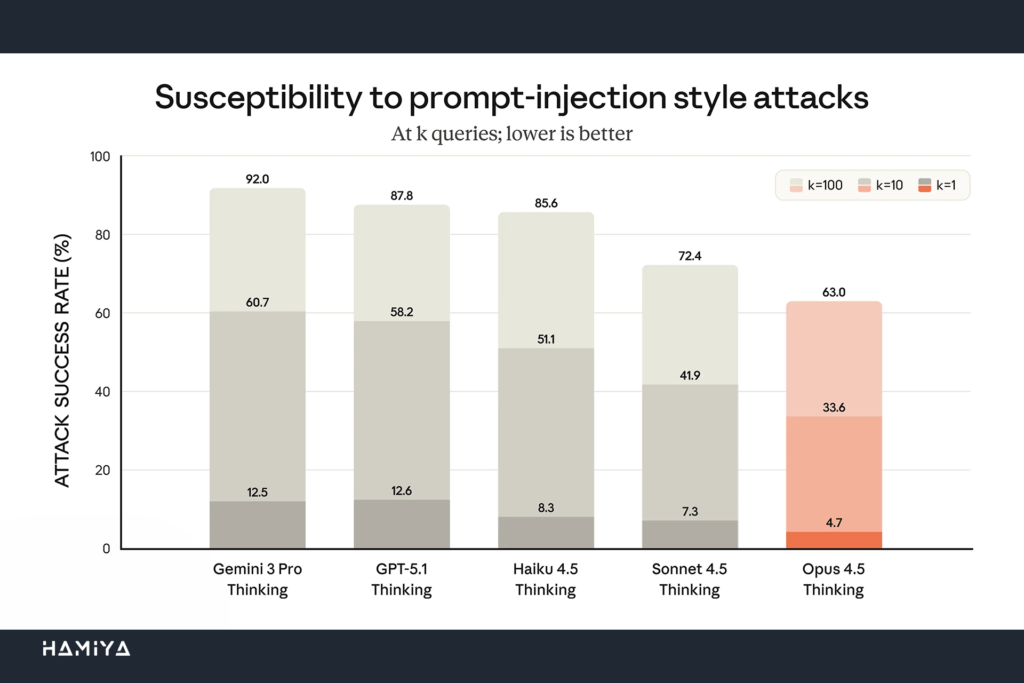
برای کسب اطلاعات دقیقتر و جامعتر در مورد تمامی ارزیابیهای فنی و اقدامات امنیتی انجامشده، کاربران میتوانند جزئیات کامل و توضیحات مفصل را در کارت سیستم Claude Opus 4.5 که به منظور شفافیت و ایمنی و همسوسازی هوش مصنوعی منتشر شده است، مطالعه نمایند.
ابزارهای جدید API: کنترل تلاش و کارایی توکن در پلتفرم توسعهدهندگان Claude
با افزایش هوشمندی مدلهای زبان بزرگ (LLM) مانند Claude Opus 4.5، قابلیت آنها در حل مسائل با استفاده از گامهای کمتر بهبود مییابد. این پیشرفت به معنای نیاز به عقبنشینیهای کمتر، کاوش تکراری کمتر و استدلالهای کمتر پرحرف (verbose) است. در نتیجه، Claude Opus 4.5 برای دستیابی به نتایج مشابه یا حتی بهتر نسبت به مدلهای پیشین خود، از تعداد توکنهای (Token) به مراتب کمتری استفاده میکند، که نشاندهنده کارایی توکن (Token Efficiency) چشمگیر این مدل مرزی (Frontier Model) است.

با این حال وظایف مختلف نیازمند مصالحهها (tradeoffs) متفاوتی هستند. در برخی موارد، توسعهدهندگان ترجیح میدهند که یک مدل زمان و انرژی بیشتری را صرف فرآیند تفکر و استدلال درباره یک مسئله کند؛ در حالی که در مواقع دیگر، یک پاسخ سریعتر و چابکتر (nimble) مورد نظر است. با معرفی پارامتر تلاش (Effort Parameter) جدید در رابط برنامهنویسی کاربردی (API) مدل Claude، شرکت Anthropic این امکان را به توسعهدهندگان میدهد تا تصمیم بگیرند که آیا هدفشان به حداقل رساندن زمان و اقتصاد مدلهای هوش مصنوعی (AI Model Economics) (هزینه توکن) است یا به حداکثر رساندن قابلیت و کیفیت خروجی. این پارامتر، عنصری کلیدی در توسعه و پیادهسازی ایجنتهای هوش مصنوعی (AI Agents) خواهد بود.
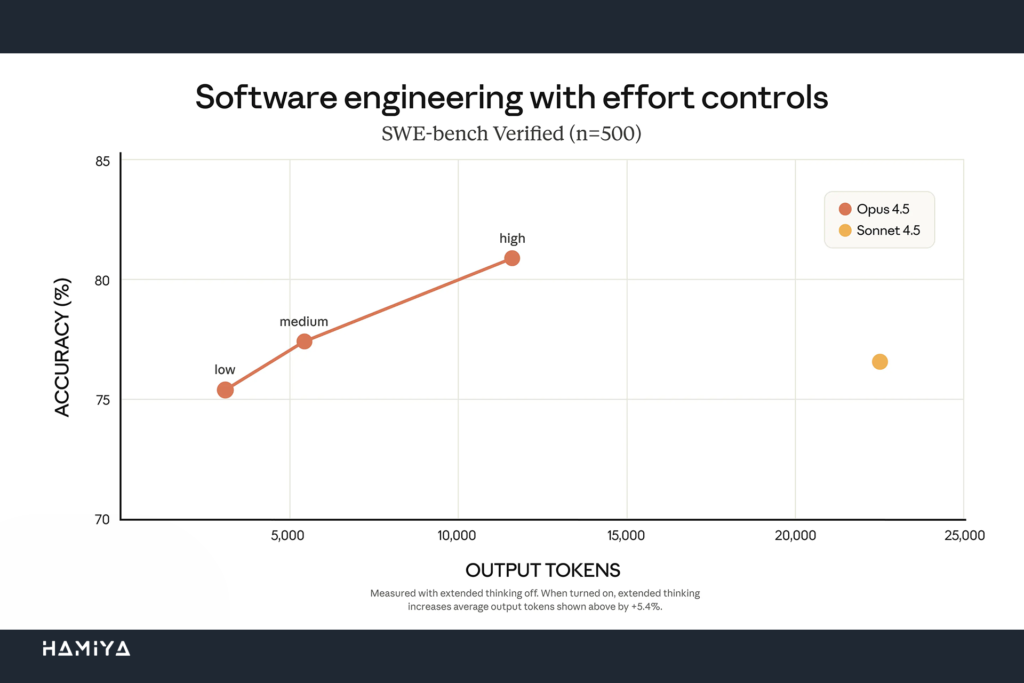
هنگامی که Opus 4.5 بر روی سطح تلاش “متوسط” تنظیم میشود، عملکرد آن در بنچمارک SWE-bench Verified دقیقاً با بالاترین امتیاز مدل Sonnet 4.5 برابری میکند. اما نکته قابل توجه این است که در این حالت، ۷۶ درصد توکنهای خروجی کمتری مصرف میشود. زمانی که این مدل بر روی بالاترین سطح تلاش خود تنظیم میشود، عملکرد Sonnet 4.5 را تا ۴.۳ واحد درصد بهبود میبخشد، در حالی که همچنان ۴۸ درصد توکن کمتری مصرف میکند. این دادهها برتری Opus 4.5 را بهعنوان بهترین مدل کدنویسی با تمرکز بر کارایی توکن تأیید میکند.
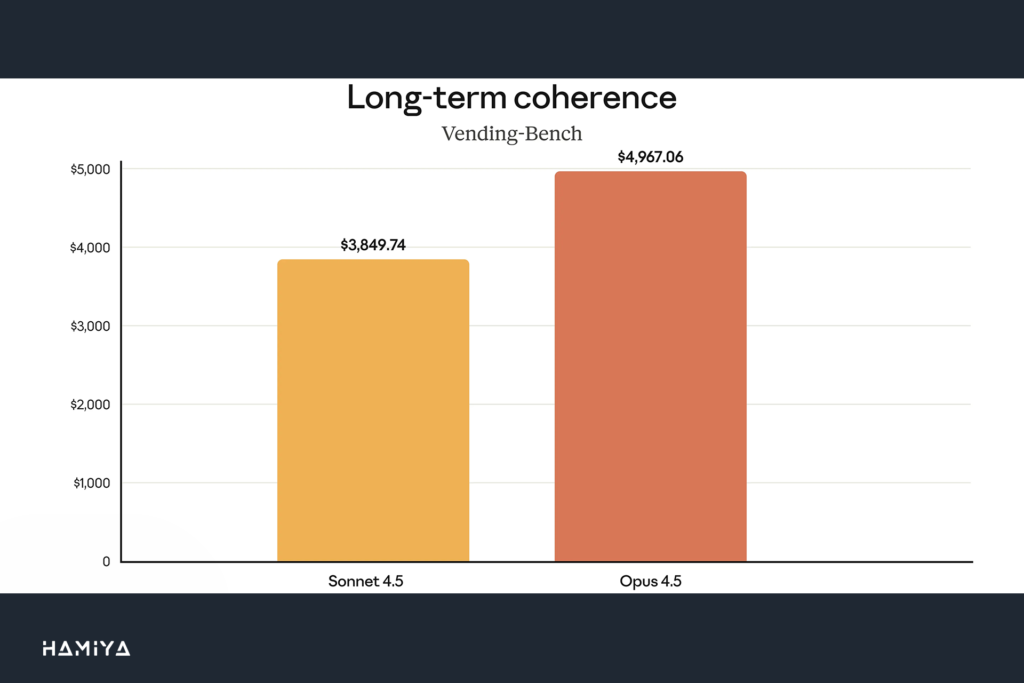
با ترکیب قابلیتهای کنترل تلاش (effort control)، فشردهسازی زمینه (Context Compaction) و استفاده پیشرفته از ابزارها در Claude Opus 4.5، سیستم قادر است در طولانی مدت فعال بماند، کارهای بیشتری را به سرانجام برساند و به میزان کمتری به مداخلات انسانی نیاز پیدا کند. این ویژگیها زمینه را برای اتوماسیون وظایف پیچیده توسط ایجنتهای هوش مصنوعی فراهم میآورد.
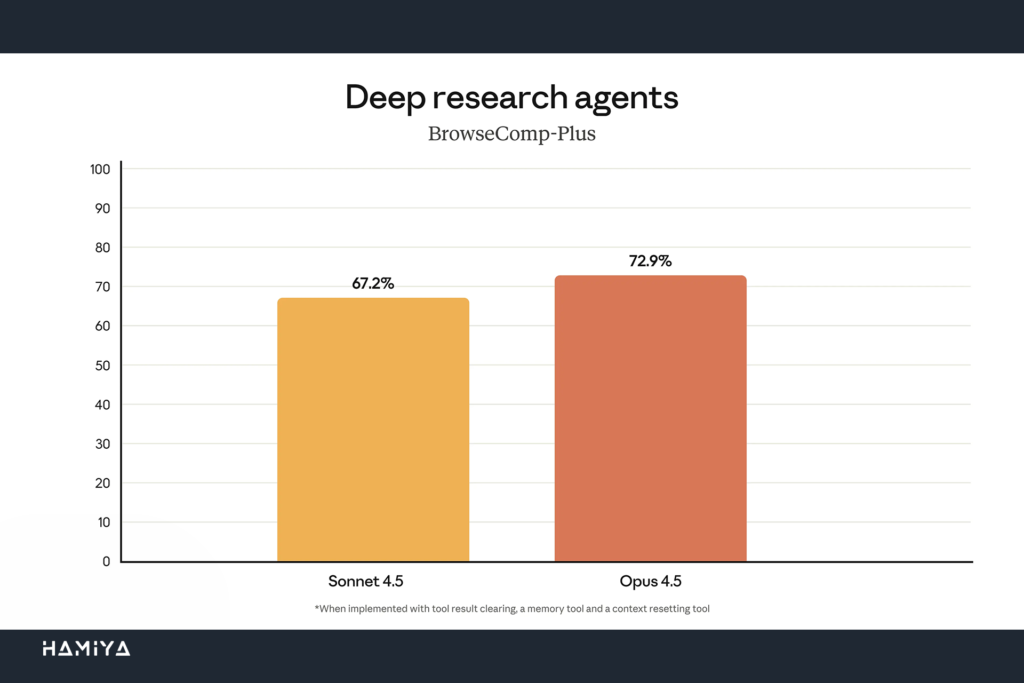
قابلیتهای بهبودیافتهی مدیریت زمینه و محتوا (context management) و حافظهی مدل، میتوانند عملکرد در وظایف عاملمحور (agentic tasks) را به طور چشمگیری افزایش دهند. علاوه بر این، Opus 4.5 در مدیریت یک تیم از عوامل فرعی (subagents) نیز بسیار مؤثر عمل میکند و امکان ساخت سیستمهای چندعاملی (Multi-agent Systems) پیچیده و با هماهنگی بالا را فراهم میسازد. در آزمایشهای داخلی شرکت Anthropic، ترکیب تمامی این تکنیکها، عملکرد Opus 4.5 را در یک ارزیابی تحقیقات عمیق تقریباً ۱۵ واحد درصد ارتقا داده است، که نشاندهندهی قابلیتهای بینظیر این مدل در استفاده از کامپیوتر برای پژوهشهای گسترده است.
شرکت Anthropic متعهد است که پلتفرم توسعهدهندهی خود (Developer Platform) را در طول زمان به طور فزایندهای منعطفتر (composable) و ترکیبیتر سازد. هدف، ارائه ابزارهای لازم به توسعهدهندگان است تا بتوانند دقیقاً همان چیزی را که نیاز دارند، با کنترل کامل بر کارایی توکن، استفاده از کامپیوتر، عملکرد ابزار و مدیریت زمینه بسازند. این رویکرد، توسعه با هوش مصنوعی را به سطحی جدید از سفارشیسازی و بهینهسازی ارتقا میدهد.
نوآوریهای کاربری: از Claude Code دسکتاپ تا چت بیپایان و افزونههای Chrome/Excel
محصولات نوآورانهای مانند Claude Code بهخوبی نشان میدهند که ترکیب قابلیتهای Claude Opus 4.5 با ارتقاهای پلتفرم توسعهدهندهی شرکت Anthropic میتواند چه دستاوردهایی را ممکن سازد. Claude Code با تکیه بر بهترین مدل کدنویسی، دو پیشرفت کلیدی را تجربه کرده است. نخست، “حالت برنامهریزی (Plan Mode)” اکنون قادر است برنامههای وظیفهی بسیار دقیقتری را طراحی کرده و آنها را به شکل جامعتری به اجرا درآورد. این بدان معناست که Claude پیش از آغاز کار، سؤالات توضیحی لازم را مطرح میکند و سپس یک فایل برنامهریزی قابل ویرایش (plan.md) برای کاربر ایجاد میکند تا قبل از اجرا، شفافیت و کنترل بیشتری بر فرآیند مهندسی نرمافزار فراهم آید.
از دیگر تحولات مهم، دسترسی به Claude Code در قالب برنامهی Claude Code دسکتاپ است. این ویژگی جدید به کاربران اجازه میدهد تا چندین نشست محلی و از راه دور را به صورت موازی اجرا کنند. برای مثال، این امکان فراهم میشود که یک ایجنت هوش مصنوعی (AI Agent) به رفع باگها بپردازد، یک عامل دیگر تحقیقات مربوط به مخازن کد (GitHub) را انجام دهد و عامل سومی مسئولیت بهروزرسانی مستندات فنی را بر عهده بگیرد. این معماری سیستمهای چندعاملی قابلیتهای استفاده از کامپیوتر و توسعه با هوش مصنوعی را به طور قابل توجهی گسترش میدهد.
برای کاربران برنامه اصلی Claude، مشکل قطع شدن مکالمات طولانیمدت برطرف شده و امکان چت بیپایان (Long Conversations) فراهم آمده است. Claude اکنون به طور خودکار زمینههای قبلی را در صورت لزوم خلاصه میکند، که این امر به مدیریت محتوا و زمینه (Context Management) مؤثر و تداوم چت کمک شایانی میکند. علاوه بر این، Claude for Chrome—که به مدل زبان بزرگ (LLM) اجازه میدهد وظایف را مستقیماً در تبهای مرورگر انجام دهد—اکنون برای تمام کاربران Max در دسترس است. همچنین، دسترسی بتا (beta access) به Claude for Excel، که قابلیت تحلیل و کار با صفحات گسترده را فراهم میسازد، از 25 نوامبر 2025 برای کلیهی کاربران Max، Team و Enterprise گسترش یافته است. هر یک از این بهروزرسانیهای کاربری، از عملکرد پیشرو Claude Opus 4.5 در زمینهی استفاده از کامپیوتر، تحلیل دادهها و اتوماسیون وظایف پیچیده بهره میبرند.
برای کاربران Claude و Claude Code که به Opus 4.5 دسترسی دارند، محدودیتهای اختصاصی مربوط به این مدل مدل مرزی حذف شده است. برای کاربران اشتراکهای Max و Team Premium، شرکت Anthropic محدودیتهای کلی استفاده (usage limits) را افزایش داده است. این به معنای دسترسی تقریباً به همان تعداد توکنهای Opus است که پیشتر برای مدل Sonnet در دسترس بود. این تغییرات در جهت تضمین این امر است که کاربران بتوانند از Opus 4.5 برای کارهای روزمره و توسعه با هوش مصنوعی به آسانی استفاده از کامپیوتر نمایند. این محدودیتهای افزایشیافته مختص Opus 4.5 هستند و پیشبینی میشود با عرضه مدلهای آینده که از این مدل پیشی میگیرند، این محدودیتها در صورت لزوم مجدداً بهروزرسانی شوند.
جمع بندی
تحلیل دقیق قابلیتها و نوآوریهای معرفی شده در این مقاله، آشکار میسازد که Claude Opus 4.5 از سوی Anthropic نه یک بهروزرسانی ساده، بلکه یک جهش بنیادین در فناوری مدلهای مرزی (Frontier Models) است. این مدل، با درهم شکستن معیارهای سنتی و کسب عنوان بهترین مدل کدنویسی در آزمونهای فنی، مرزهای توانمندیهای هوش مصنوعی را در حل مسائل پیچیده و چندسیستمی گسترش داده است. اوپوس ۴.۵ با “درک عمیق موضوع” و ظرفیت بینظیر در فرآیندهای ایجنتهای هوش مصنوعی ، متخصصان را از ضرورت مداخلههای مکرر رها میسازد؛ این خود، نمادی از اعتماد به استقلال و صلاحیت مدل در انجام وظایف با قضاوت فنی دقیق است.
این تحول، صرفاً فنی نیست، بلکه یک تغییر پارادایم اقتصادی و سازمانی را در بر دارد. تمرکز هوشمندانه Anthropic بر کارایی توکن و ارائه ابزارهایی چون پارامتر تلاش (Effort Parameter) ، نه تنها قابلیتهای ممتاز مدل را برای استفاده گستردهتر مقرونبهصرفه میسازد، بلکه یک اصل حیاتی را محقق میکند: کنترل کامل توسعهدهنده بر منابع و عملکرد. این تضمین همراه با امنیت LLM بیسابقه مدل در برابر تزریق پرامپت ، بستر لازم برای اعتماد و آزادی عمل در اکوسیستم توسعه نرمافزار را فراهم میآورد. Claude Opus 4.5 در نهایت، نویدبخش آیندهای است که در آن ابزارهای هوشمند به مثابه سرمایههای توانمند و مستقل عمل میکنند و مسیر را برای شکلگیری کارآفرینیهای یکنفره و سازمانهای چابکتر در فضای بازار، هموار میسازند.
سوالات متداول
آنتروپیک صراحتاً Claude Opus 4.5 را بهترین مدل در جهان برای کدنویسی، عاملها (Agents) و استفاده از کامپیوتر معرفی کرده است.
این مدل در آزمونهای مهندسی نرمافزار دنیای واقعی (مانند SWE-bench) پیشرفتهترین (State-of-the-Art) است و حتی در یک آزمون داخلی عملکرد مهندسی، امتیازی بالاتر از هر نامزد انسانی دیگری کسب کرد.
قیمتگذاری استاندارد برای هر میلیون توکن ورودی ۵ دلار و برای هر میلیون توکن خروجی ۲۵ دلار است. ابزارهایی مانند Prompt Caching تخفیفهای قابل توجهی را ارائه میدهند.
این مدل منسجمترین (Robustly aligned) مدل منتشر شده توسط آنتروپیک است و پیشرفت چشمگیری در مقاومت در برابر حملات تزریق پرامپت (Prompt Injection) داشته است.
Opus 4.5 با استفاده از توکنهای بسیار کمتر نسبت به مدلهای قبلی، به نتایج مشابه یا حتی بهتر دست مییابد؛ به عنوان مثال با تلاش متوسط، از ۷۶ درصد توکن خروجی کمتر استفاده میکند.
بله. با ابزار جدید پارامتر تلاش (Effort Parameter) در API، توسعهدهندگان میتوانند بین حداقل کردن زمان و هزینه یا به حداکثر رساندن قابلیت و دقت، تعادل برقرار کنند.
این بهروزرسانیها شامل عرضه گسترده Claude for Chrome و Claude for Excel، همچنین قابلیت چت بیپایان (با خلاصهسازی خودکار زمینه) در برنامههای Claude است.
بله، این مدل برای وظایف عاملمحور (Agentic Tasks) عالی است و میتواند سیستمهای چندعاملی (Multi-agent Systems) پیچیده و با هماهنگی بالا را مدیریت کند.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





