در عصری که مدلهای هوش مصنوعی (AI) با سرعت سرسامآور در حال رشد هستند و مدلهای زبانی بزرگ (LLM) مرزهای دانش را جابهجا میکنند، زیرساختهای محاسباتی به میدان اصلی نبرد اقتصادی و تکنولوژیک تبدیل شدهاند. برای دههها، واحدهای پردازش گرافیکی (GPU) ساخت انویدیا به عنوان شتابدهنده اصلی یادگیری عمیق (Deep Learning) در جهان شناخته میشدند؛ سختافزارهایی انعطافپذیر که بازار را قبضه کرده و هزینههای آموزش را تحت سیطره خود داشتند. اما این سلطه مطلق اکنون با ظهور رقیبی سرسخت و تخصصی، یعنی واحدهای پردازش تنسور TPU توسعهیافته توسط گوگل، به چالش کشیده شده است. انتخاب استراتژیک گوگل مبنی بر آموزش کامل مدل عظیم Gemini 3 Pro بر روی سختافزار اختصاصی TPU، نه یک تصمیم فنی صرف، بلکه یک دهنکجی آشکار به انحصار موجود در بازار سختافزار هوش مصنوعی بود. این اقدام، زنگ خطر را برای شرکتهای وابسته به GPU به صدا درآورد و پرسش محوری را پیش کشید: در این رقابت فزاینده برای تربیت ابر-مدلها، کدام معماری، اعم از ASIC تخصصی (TPU) یا پردازش موازی عمومی (GPU)، برتری کارایی را در فازهای حیاتی آموزش و استنتاج تضمین میکند؟ مقاله پیش رو به عنوان یک راهنمای جامع و فنی، به مقایسه عمیق تفاوتهای معماری، ملاحظات اکوسیستمی (از جمله هزینه) و عملکرد این دو تراشه میپردازد تا متخصصان، محققان و مدیران زیرساخت بتوانند آگاهانهترین تصمیم را در مسیر بهینهسازی محاسبات یادگیری عمیق اتخاذ نمایند.
فهرست مطالب
نخستین رویارویی با مفهوم واحد پردازش تنسور (TPU – Tensor Processing Unit)، سالها پیش، در حین استفاده از محیط محاسباتی ابری Google Colab رخ داد. در کنار انتخابهای مرسوم برای سختافزار رایانهای شامل واحد پردازش مرکزی (CPU) و واحد پردازش گرافیکی (GPU – Graphics Processing Unit)، گزینهای مجهول و سوم با عنوان TPU جلب توجه میکرد. در آن مقطع زمانی، درک تمایز عملکردی این شتابدهنده هوش مصنوعی (AI Accelerator) و دلایل ارائه آن توسط شرکت گوگل بهعنوان یک موتور جایگزین برای اجرای کدهای یادگیری عمیق بهطور کامل میسر نبود.
با گذر زمان و پیشرفتهای اخیر، چشمانداز زیرساخت ابری (Cloud Infrastructure) و محاسبات هوش مصنوعی دستخوش دگرگونیهای چشمگیری شده است. بهعنوان مثال بارز، جدیدترین مدل زبانی بزرگ جمینای ۳ پرو (Gemini 3 Pro) شرکت گوگل، بهطور انحصاری بر روی واحدهای پردازش تنسور (TPU) سفارشی این شرکت آموزش (Training) داده شده و وابستگی به GPUهای شرکت انویدیا (Nvidia) را کنار گذاشته است. این رویکرد نه تنها نشاندهنده اعتماد فزاینده گوگل به سختافزار هوش مصنوعی داخلی خود است، بلکه بر اهمیت حیاتی و روزافزون TPUها در توسعه سامانههای هوش مصنوعی مدرن و اجرای بهینه محاسبات تنسوری (Tensor Computations) تأکید میورزد.
هم GPUها و هم TPUها بهعنوان شتابدهندههای هوش مصنوعی با کارایی بالا، نقش حیاتی در حوزهی یادگیری عمیق ایفا میکنند، بااینحال، دارای منشأ معماری متفاوتی هستند. GPUها در ابتدا بهعنوان تراشههایی که برای رندر کردن گرافیک سهبُعدی بهینهسازی شده بودند، طراحی شدند؛ سپس، قابلیتهای گسترده آنها در پردازش موازی (Parallel Processing)، این واحدها را برای انجام حجم کاری سنگین شبکههای عصبی بسیار کارآمد ساخت. در مقابل، TPUها توسط شرکت گوگل، از ابتدا و بهطور اختصاصی با هدف شتاب بخشیدن به محاسبات تنسوری و حجم کاری شبکههای عصبی و با معماری هدفمند برای هوش مصنوعی مهندسی شدهاند.
در این مقاله، تیم نویسندگان هامیا ژورنال به بررسی و مقایسه GPU و TPU در زمینههای حیاتی آموزش مدلها (Training) و استنتاج (Inference) خواهند پرداخت. در ادامه، چگونگی ادغام هر یک از این سختافزارهای هوش مصنوعی در چارچوبهای نرمافزاری رایج نظیر تنسورفلو (TensorFlow) و پایتورچ (PyTorch) و همچنین شرایط بهینهای که در آن یکی از این شتابدهندههای هوش مصنوعی ممکن است بر دیگری ارجحیت داشته باشد، بهدقت تحلیل خواهد شد.
تفاوت معماری GPU و TPU: از هستههای تنسور (Tensor Cores) تا آرایههای سیستولیک (ASIC)
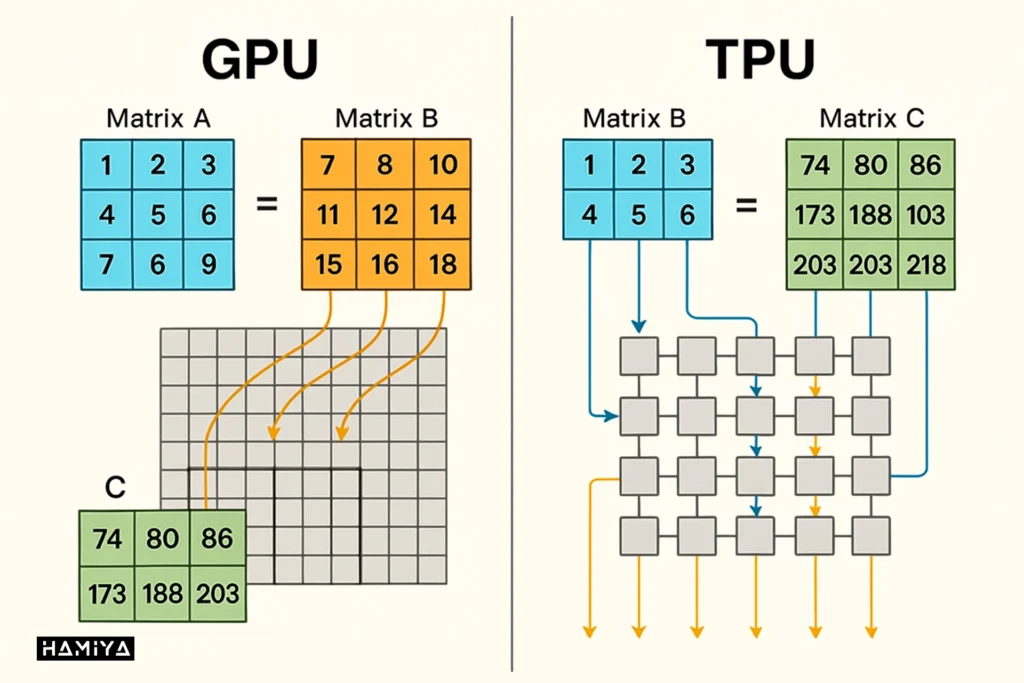
GPUها (واحد پردازش گرافیکی) با ساختاری مبتنی بر هزاران هستهی پردازشی کوچک طراحی شدهاند که بهطور خاص برای اجرای پردازش موازی (Parallel Processing) بهینهسازی شدهاند. این ماهیت، انعطافپذیری فوقالعادهای به آنها میبخشد تا بتوانند حجم گستردهای از عملیات را بهصورت همزمان به انجام رسانند که برای محاسبات ماتریسی و برداری در یادگیری عمیق (Deep Learning) بسیار مناسب است. GPUهای مدرن (مانند سری A100/H100 انویدیا) همچنین با افزودن واحدهای تخصصی تحت عنوان هستههای تنسور (Tensor Cores) تقویت شدهاند که شتابدهندهی عملیات ضرب ماتریسی با دقت ترکیبی (Mixed-Precision) هستند. علاوه بر این، این سختافزار هوش مصنوعی دارای پهنای باند حافظه داخلی (On-Board Memory Bandwidth) بسیار بالایی (مانند VRAM) هستند که انتقال سریع دادهها را برای آموزش مدلها تضمین میکند. در نتیجه، GPU یک معماری کامپیوتر انعطافپذیر ارائه میدهد که توانایی مدیریت طیف وسیعی از محاسبات (نه صرفاً شبکههای عصبی) را دارد که ریشه در میراث آنها در گرافیک و محاسبات عمومی دارد.
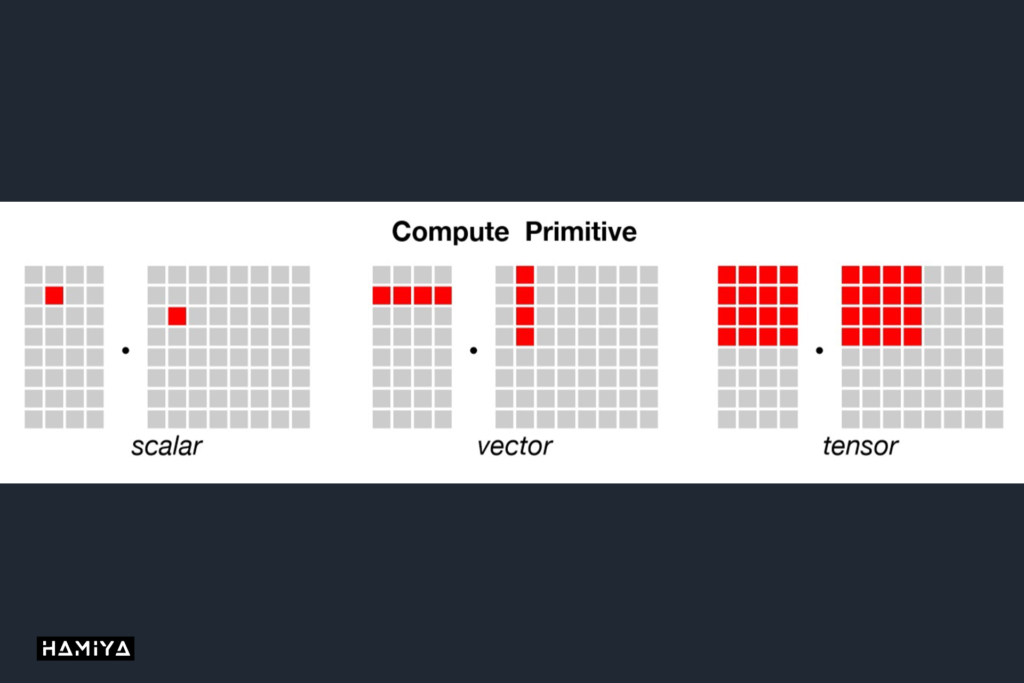
در نقطه مقابل، TPUها (واحد پردازش تنسور) بهعنوان مدارهای مجتمع کاربرد-خاص (ASIC – Application-Specific Integrated Circuits) طراحی شدهاند که از ابتدا توسط طراحی ASIC گوگل صرفاً برای وظایف هوش مصنوعی (AI) و یادگیری ماشین ساخته شدهاند. برخلاف معماری پردازش موازی GPU، یک تراشه TPU بهجای هستههای عمومی CUDA، حاوی واحدهای بزرگ ضرب ماتریسی (مانند ضربکنندههای آرایه سیستولیک 128 در 128) در کنار تعداد محدودی واحد برداری و اسکالر است. این معماری بسیار تخصصی بدان معناست که TPUها در عملیات تنسوری (محاسبات تنسوری که هستهی اصلی شبکههای عصبی هستند) عملکردی فوقالعاده دارند و اغلب میتوانند توان عملیاتی (Throughput) و کارایی انرژی بالاتری نسبت به یک GPU با قیمت مشابه در این وظایف خاص ارائه دهند. با این حال، به دلیل داشتن هستههای عمومی کمتر و اتکای زیاد به دریافت دستههای بزرگ محاسبات (Large Batches) برای بهرهبرداری کامل از واحدهای ماتریسی، این شتابدهنده هوش مصنوعی انعطافپذیری کمتری برای پردازشهای دلخواه (Arbitrary) یا بسیار پویا (Highly Dynamic) نسبت به GPUها دارد.
یکی دیگر از تمایزات اساسی در معماری کامپیوتر این دو شتابدهنده، به نحوه مقیاسگذاری آنها در زیرساخت ابری باز میگردد. سیستمهای مبتنی بر GPU غالباً از اتصالات پرسرعتی مانند NVLink (درون یک سرور) یا InfiniBand (بین سرورها) برای امکانپذیر ساختن آموزش چند-GPU استفاده میکنند. در مقابل، TPUها بهگونهای مهندسی شدهاند که در قالب “پادهای TPU (TPU Pods)” مقیاسپذیر باشند. این پادها از یک اتصال داخلی بینتراشهای (Interchip Interconnect) اختصاصی و بسیار پرسرعت (مانند شبکه تورس D2 در نسلهای TPU v4/v5) برای آموزش موازی با اتصال محکم (Tightly Coupled) بهره میبرند. پادهای TPU گوگل میتوانند صدها تراشه TPU را بههم متصل کنند که این امر مقیاسپذیری تقریباً خطی را برای آموزش مدلهای هوش مصنوعی بسیار بزرگ فراهم میسازد. این یکپارچگی محکم در معماری و شبکه، یکی از دلایلی است که گوگل میتواند مدلهای عظیمی مانند Gemini را با کارایی بالا بر روی TPUها آموزش دهد؛ چرا که کل پشتهی سختافزار سیلیکونی سفارشی و شبکه تحت کنترل خود شرکت قرار دارد. در مقایسه GPU و TPU، اگرچه GPUها نیز میتوانند بهصورت خوشهای (Clusters) مقیاسگذاری شوند، اما این فرآیند معمولاً با سربار (Overhead) کمی بیشتر در تنظیم آموزش توزیعشده همراه است و اغلب برای دستیابی به توان عملیاتی تجمعی مشابه، توان مصرفی بیشتری را میطلبند.
موضوع حافظه یکی دیگر از ملاحظات حیاتی در مقایسه GPU و TPU است. GPUهای پیشرفتهی امروزی غالباً دارای حجم بزرگی از VRAM داخلی با پهنای باند حافظه بسیار بالا هستند (برای مثال ۸۰ گیگابایت در انویدیا A100). در مقابل، TPUها به سمت یک طراحی حافظه توزیعشده TPU گرایش دارند؛ یعنی هر هستهی TPU دارای حافظه محلی پرسرعت خود (مانلاً دهها گیگابایت HBM) است، اما مدلهای هوش مصنوعی بزرگ میان تراشههای متعددی بهطور مساوی توزیع میشوند. این تفاوت VRAM در GPU و TPU به این معناست که GPUها گاهی اوقات میتوانند یک مدل بزرگتر را در یک دستگاه واحد جای دهند، در حالی که TPUها بر این فرض طراحی شدهاند که بار محاسباتی و مدل را باید بین هستههای متعدد پارتیشنبندی کرد. رویکرد گوگل با TPUها بر “گسترش مقیاس (Scale Out)” با استفاده از تعداد زیادی تراشه و پردازش موازی، بهجای تکیه صرف بر حافظه یک تراشه واحد متمرکز شده است. در عمل، برای مدلهای بسیار بزرگ، هر دو معماری نیازمند تقسیم مدل بین دستگاههای متعدد برای آموزش و استنتاج هستند، اما تنظیمات مبتنی بر GPU ممکن است از تعداد کارتهای کمتر با حافظه بیشتر استفاده کنند، در حالی که تنظیمات TPU از تعداد تراشههای بیشتر با اتصالات داخلی سریعتر و سفارشی بهره میبرند.
GPU در مقابل TPU برای آموزش مدلها: مقایسه سرعت، هزینه و الزامات اکوسیستم
در غالب بخشهای صنعت هوش مصنوعی (AI)، GPUها (واحد پردازش گرافیکی) بهعنوان پرکارترین شتابدهنده هوش مصنوعی (AI Accelerator) برای آموزش مدلهای یادگیری عمیق (Deep Learning) شناخته میشوند. توسعهی فریمورکهای محوری مانند PyTorch در مقابل TensorFlow در ابتدا با هدف بهرهمندی از شتابدهی GPU آغاز شد و اکثریت قریب به اتفاق مدلهای متنباز (از شبکههای عصبی کانولوشنی گرفته تا مدلهای زبان بزرگ (LLMs)) بر روی سختافزار GPU شرکت انویدیا آموزش (Training) دیدهاند. این امر ریشه در اکوسیستم غنی دارد: GPUها از گستره وسیعی از کتابخانههای یادگیری ماشین و ابزارهای توسعهدهنده پشتیبانی میکنند، به طوری که تقریباً تمامی کدهای تحقیقاتی و ابزارهای اشکالزدایی بر محوریت GPU طراحی شدهاند. برای مثال، اگر متخصصان در حال اجرای تنظیم دقیق (Fine-tuning) یک مدل با استفاده از فریمورک PyTorch باشند یا از کتابخانههای پیشرفته (مانند DeepSpeed یا Megatron) استفاده نمایند، نرمافزار بهصورت پیشفرض یک GPU را بهعنوان موتور پردازش موازی انتظار دارد. علاوه بر این، GPUها بهراحتی در میان ارائهدهندگان زیرساخت ابری (Cloud Infrastructure) (شامل AWS، Azure و GCP) و همچنین برای خرید در محل (On-Premise) قابل دسترسی هستند، که این انعطافپذیری را به متخصصان میدهد تا فرآیند آموزش مدلها را در محیطهای مختلف به انجام رسانند.
TPUها (واحد پردازش تنسور) در زمینهی آموزش مدلها زمانی در کانون توجه قرار میگیرند که با آموزش مدلهای عظیم یا مجموعهدادههای بسیار حجیم مواجه باشیم و امکان استفاده از زیرساخت ابری اختصاصی گوگل وجود داشته باشد. شرکت گوگل از TPUها برای آموزش و استقرار مدلهای عظیمی مانند PaLM و Gemini بر روی خوشههای بزرگ “پاد TPU” خود استفاده میکند. این شتابدهندههای هوش مصنوعی برای دستیابی به توان عملیاتی بالا بهینهسازی شدهاند: با تغذیه دستههای بزرگ داده (Large Batches) به آنها، محاسبات تنسوری را با کارایی بالا به انجام میرسانند. در سناریوهایی مانند دستهبندی تصویر در مقیاس بزرگ یا آموزش مدلهای ترنسفورمر (Transformer Models)، یک پاد TPU میتواند فرآیند آموزش را بهطور قابل توجهی سریعتر (و اغلب با کارایی انرژی GPU در مقابل TPU بالاتر) نسبت به یک خوشه GPU با قیمت معادل تکمیل کند. بهعنوان مثال، در یک مقایسه GPU و TPU ثبتشده، آموزش یک مدل ResNet-50 تنها ۱۵ دقیقه بر روی یک Cloud TPU v3 زمان برده، در حالی که همین فرآیند روی یک NVIDIA V100 GPU تقریباً ۴۰ دقیقه طول کشیده است (با حفظ اندازه دسته یکسان). این مقایسه دلالت بر این ندارد که TPUها همواره بر GPUها برتری دارند، اما برای مدلهایی که به خوبی برای معماری TPU بهینهسازی شدهاند، این واحدها میتوانند در مقیاسهای بزرگ، سرعت آموزش برتر را به ازای هر واحد هزینه ارائه دهند.
با این حال، شایان ذکر است که هر مدل یادگیری عمیق برای آموزش با TPU مناسب نیست. برای استفاده حداکثری از پتانسیل TPUها، معماری مدل و خط لولهی ورودی (Input Pipeline) باید با کامپایلر XLA (Accelerated Linear Algebra) سازگار باشد. این موضوع در عمل به این معناست که کد باید از عملیات پشتیبانینشده یا بسیار سفارشی دوری کند و بهطور ایدهآل از شکلهای ایستا (Static Shapes) برای محاسبات تنسوری استفاده نماید. TPUها بهطور معمول با مشکلات سازگاری XLA در مورد شکلهای پویا (Dynamic Shapes) یا مدلهایی که دارای کنترل-جریان (Control-flow) سنگین هستند و همچنین عملیات سفارشی خاصی که بخشی از مجموعهی پشتیبانیشدهی TensorFlow/XLA نیستند، روبرو میشوند. بهعنوان مثال، یک مدل پژوهشی با منطق زیاد در سمت پایتون، یا مدلی که به محاسبات با دقت بالا در سراسر آن نیاز دارد، ممکن است روی TPU کندتر اجرا شود یا بدون تغییرات اساسی اصلاً اجرا نشود. در مقابل، GPUها میتوانند تقریباً هر نوع عملیاتی را اجرا کنند؛ از مدلهای پویای فریمورک PyTorch با عبارات شرطی گرفته تا کرنلهای سفارشی CUDA؛ که این ویژگی آنها را برای آزمایش و نوآوری در فاز تحقیق انعطافپذیرتر میسازد. همچنین، اشکالزدایی روی GPUها عموماً سادهتر است، در حالی که در TPUها، محدودیتهای اجرای گراف کامپایلشده میتواند فرآیند اشکالزدایی را دشوارتر سازد.
عامل دیگری که باید مد نظر قرار داد، ملاحظات هزینه و دسترسی است. GPUها در چند سال اخیر گران بوده و تقاضای بسیار بالایی داشتهاند که در رونقهای اخیر هوش مصنوعی بهطور کنایهآمیز به “مالیات انویدیا” شهرت یافته است؛ در حالی که گوگل دسترسی به TPU را ارائه میدهد که میتواند از نظر محاسباتی که در اختیار میگذارد، از لحاظ هزینه رقابتی باشد. در واقع، گزارش آموزش مدلهای عظیم مانند Gemini 3 توسط گوگل نشان میدهد که استفاده از TPUها امکان آموزش در مقیاسهای بزرگتر و طولانیتر را با هزینه کلی پایینتری نسبت به آنچه با GPUها ممکن بود، فراهم کرده است. با این حال، دسترسی به TPU عمدتاً محدود به Google Cloud است. اگر هدف آموزش مدلها روی سرورهای اختصاصی (On-Premise) یا یک ارائهدهنده زیرساخت ابری دیگر باشد، TPUها گزینهای در دسترس نیستند؛ در این موارد باید از GPUها بهعنوان سختافزار هوش مصنوعی استفاده کرد. لذا، تصمیمگیری اغلب به اکوسیستم و مقیاس پروژه وابسته است: در داخل گوگل یا برای پروژههای TensorFlow در مقیاس بسیار بزرگ، TPUها میتوانند فوقالعاده باشند؛ اما برای اکثر موارد دیگر (بهویژه با استفاده از فریمورک PyTorch یا نیاز به چند-ابر/آموزش در محل)، GPUها همچنان بهعنوان استاندارد اصلی باقی میمانند.
عملکرد استنتاج (Inference): TPU برای توان عملیاتی بالا یا GPU برای تأخیر کم؟
زمانی که بحث به استنتاج (Inference) میرسد؛ یعنی بهکارگیری مدلهای آموزشدیدهی هوش مصنوعی برای انجام پیشبینی در مرحله استقرار (Deployment)؛ GPUها (واحد پردازش گرافیکی) بهطور سنتی انتخاب پیشفرض برای ارائهی خدمات با عملکرد بالا در صنعت بودهاند. GPUهای مدرن برای عملیات ماتریسی و برداری در فاز استنتاج مدل بهشدت بهینهسازی شدهاند. برای مثال، جدیدترین GPUهای انویدیا دارای ویژگیهایی مانند موتورهای ترنسفورمر (Transformer Engines) و پشتیبانی از دقتهای پایینتر (FP8/INT8) هستند که بهمنظور افزایش سرعت استنتاج مدلهای زبانی بزرگ (LLM Inference) و کاهش مصرف انرژی طراحی شدهاند. مجموعه ابزارهای مرتبط با استنتاج GPU بسیار بالغ و گسترده است: فریمورکهای بهینهسازی مانند TensorRT برای استنتاج GPU، ONNX Runtime یا کتابخانههای تولید متن Hugging Face همگی GPUها را هدف قرار میدهند تا به تأخیر استنتاج (Inference Latency) پایین دست یابند. در نتیجه، بسیاری از سرویسهای محبوب هوش مصنوعی، از جمله سرویس ChatGPT شرکت OpenAI، روی نمونههای GPU NVIDIA A100/H100 اجرا میشوند که برای استنتاج مدلهای ترنسفورمر بسیار مناسب و بهینه هستند.
TPUها (واحد پردازش تنسور) نیز، بهویژه در محصولات داخلی شرکت گوگل، نقش مهمی در فاز استنتاج ایفا میکنند. از آنجایی که TPUها از ابتدا با معماری خاص برای محاسبات تنسوری طراحی شدهاند، میتوانند برای استنتاج مدل در مقیاس بالا، فوقالعاده سریع و کارآمد عمل کنند. گوگل علناً اعلام کرده است که از TPUها در سرویسهایی مانند جستجو (Search)، Google Photos و Google Maps برای پشتیبانی از مدلهای یادگیری ماشین در مرحله تولید (Production) استفاده میشود. برای مدلهای بزرگ، یک خوشهی TPU v4 یا v5 میتواند درخواستهای زیادی را بهصورت پردازش موازی با توان عملیاتی بالا و تأخیر قابل قبول ارائه دهد. در واقع، TPUها با در نظر گرفتن هر دو فاز آموزش و استنتاج ساخته شدهاند؛ حتی نسل اول TPU (v1) صرفاً برای استنتاج در سرویسهایی مانند ترجمه (Translate) مستقر شد و نسلهای بعدی قابلیتهای آموزش مدلها را نیز اضافه کردند. TPUهای امروزی (مانند عملکرد TPU v5e) بهطور خاص برای استنتاج با توان عملیاتی بالا بهینهسازی شدهاند و بهبودهایی را در توان عملیاتی به ازای هر واحد هزینه، بهویژه برای ارائهی کارآمد مدلها در زیرساخت ابری (Cloud Infrastructure)، ارائه میدهند.

با این حال، باید در نظر داشت که خارج از زیرساخت ابری Google Cloud و محصولات داخلی این شرکت، استفاده از TPU در استنتاج چندان رایج نیست. اغلب سازمانها به دلیل راحتی، انعطافپذیری و پشتیبانی گستردهتر از GPUها، یا گاهی شتابدهندههای هوش مصنوعی تخصصی استنتاج (مانند AWS Inferentia)، استفاده میکنند. اگر هدف، استقرار مدل در AWS یا Azure یا در محل کار (on-prem) باشد، تقریباً بهطور قطع از یک GPU یا CPU استفاده میشود، زیرا TPUهای گوگل در آنجا در دسترس نیستند. با وجود این، اگر در اکوسیستم Google Cloud قرار دارید و مدل شما با TensorFlow ساخته شده است، میتوانید یک نمونهی TensorFlow Serving را که توسط Cloud TPU پشتیبانی میشود، مستقر کنید تا به طور بالقوه کارایی بالاتری را در مواجهه با دستههای بزرگ (Large Batches) تجربه کنید. استنتاج TPU بهویژه زمانی بهینه عمل میکند که نیاز به ارائهی خدمات برای مدلهای بسیار بزرگ یا حجم بالایی از درخواستها داشته باشید و هدف، به حداقل رساندن هزینه به ازای هر کوئری باشد. گوگل اشاره کرده است که استنتاج مبتنی بر TPU میتواند در مقیاس، مقرون به صرفهتر باشد، حتی اگر تأخیر خام (Raw Latency) آن مشابه GPU باشد. این مزیت ناشی از سختافزار تخصصی TPU و بهینهسازیهای جامع مرکز داده گوگل است.
در مورد استنتاج لبه (Edge Inference) یا موبایل، لازم است اشاره کنیم که اصطلاح “TPU” در Edge TPU گوگل (یک شتابدهنده کوچک برای دستگاههای اینترنت اشیا (IoT)) و NPUهایی که در گوشیهای هوشمند (مانند تراشهی Tensor گوگل یا Neural Engine اپل) یافت میشوند، نیز به چشم میخورد. این واحدها برای استنتاج کممصرف روی دستگاه تخصصی شدهاند. در مقابل، GPUها نیز نسخههایی مانند NVIDIA Jetson را برای هوش مصنوعی لبه (Edge AI) ارائه میدهند. اگرچه سناریوهای لبه از حوزه اصلی مقایسه GPU و TPU ما فراتر است، اما بر یک روند کلی تأکید میکند: شتابدهندههای عصبی تخصصی (شامل TPUها و NPUها) تمایل به ارائهی کارایی انرژی بهتری برای استنتاج دارند، در حالی که GPUها انعطافپذیری بیشتری را ارائه میدهند و زمانی که سختافزار تخصصی در دسترس نیست، بهعنوان یک راهحل عمومی برای پردازش موازی مورد استفاده قرار میگیرند.
جمع بندی
همانطور که در این تحلیل جامع روشن شد، رقابت میان GPUها و TPUها صرفاً یک نبرد فنی میان دو قطعه سیلیکونی نیست، بلکه تقابلی بر سر آینده معماری هوش مصنوعی و فلسفه زیرساختهای محاسباتی است. مقاله حاضر، با تمرکز بر تفاوتهای بنیادین در معماری ASIC و طراحی چندمنظوره، همچنین بررسی دقیق کارایی آنها در مراحل حیاتی آموزش مدلها و استنتاج، یک نقشه راه شفاف برای متخصصان فراهم آورد.
در نهایت، هیچ پیروز مطلقی وجود ندارد؛ انتخاب بهینه، ریشه در آزادی استراتژیک هر پروژه دارد. GPUها به دلیل اکوسیستم نرمافزاری بالغ انویدیا (مانند PyTorch و ابزارهای اشکالزدایی)، انعطافپذیری بیبدیلی برای آزمایش، نوآوری و استقرار در محیطهای ابری مختلف (Multi-Cloud) فراهم میآورند. در مقابل، TPUهای گوگل نشان دادند که در مقیاسهای کلان و برای مدلهای بسیار بزرگ، با بهینهسازی توان عملیاتی بالا و کاهش هزینه به ازای هر کوئری، توان رقابتی کمنظیری دارند و انتخابی قدرتمند در اکوسیستم بسته Google Cloud محسوب میشوند. در فضایی که نوآوری شتابدهندههای عصبی، مانند TPU v5e یا هوش مصنوعی لبه (Edge AI)، مرزهای کارایی و مصرف انرژی را جابهجا میکنند، تصمیمگیری دیگر تنها به قدرت محاسباتی خام خلاصه نمیشود، بلکه به نیت جستجوی دقیق شما برای “سرعت آموزش”، “تأخیر استنتاج” و “مقیاسپذیری” بستگی دارد. لذا، با اتکا به دانش بهدستآمده از این مقایسه تخصصی، اکنون هر تیم میتواند با آگاهی کامل، شتابدهندهای را برگزیند که به بهترین شکل، اهداف اقتصادی و فنی پروژه آنها را محقق سازد.
سوالات متداول
GPU یک پردازنده چندمنظوره با هستههای کوچک موازی (CUDA/Tensor Cores) است، اما TPU یک مدار مجتمع کاربرد-خاص (ASIC) طراحی شده از پایه برای محاسبات تنسوری با استفاده از آرایههای سیستولیک است.
TPUها (به ویژه در قالب TPU Pods) برای توان عملیاتی بالا (Throughput) و آموزش مدلهای عظیم در مقیاس بزرگ بهینهتر هستند، در حالی که GPUها انعطافپذیری بیشتری در انواع مدلها ارائه میدهند.
TPUها میتوانند در مقیاسهای بسیار بزرگ و در بستر Google Cloud، از نظر هزینه به ازای هر کوئری یا هزینه کلی آموزش، رقابتیتر یا مقرون به صرفهتر از خوشههای GPU باشند (“مالیات انویدیا”).
دلیل اصلی، انعطافپذیری و بلوغ اکوسیستم نرمافزاری GPU (مانند PyTorch) است. GPUها بدون نیاز به سازگاری با کامپایلر XLA، هر مدل یا عملیات سفارشی را اجرا میکنند.
GPUها انتخاب استاندارد صنعت برای تأخیر (Latency) کم و استنتاج مدلهای ترنسفورمر هستند. TPUها (مانند TPU v5e) در استنتاج با توان عملیاتی بالا (High Throughput) و در حجمهای عظیم داخلی گوگل، برتری دارند.
بله، PyTorch از طریق کتابخانه PyTorch/XLA میتواند بر روی TPU اجرا شود، اما مدل و خط لوله ورودی باید با محدودیتهای کامپایلر XLA (مانند استفاده از شکلهای ایستا) سازگار باشند.
Edge TPU یا Coral، یک شتابدهنده کوچک و کممصرف است که توسط گوگل برای اجرای سریع استنتاج (Inference) روی دستگاههای اینترنت اشیا (IoT) و هوش مصنوعی لبه (Edge AI) طراحی شده است.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️