
هوش مصنوعی، به عنوان یکی از فناوریهای پیشرو و تأثیرگذار عصر حاضر، در حال دگرگون کردن صنایع مختلف است. اما این فناوری قدرتمند، همچون هر ابزار دیگری، میتواند تحت تأثیر بایاس قرار گیرد. بایاس هوش مصنوعی به معنای وجود تعصبات و گرایشهای ناخواسته در مدلهای یادگیری ماشین است که میتواند منجر به نتایج ناعادلانه و مغرضانه شود. این تعصبات ریشه در دادههای آموزشی، الگوریتمها و حتی درک انسان از جهان دارد.
آیا تا به حال به این فکر کردهاید که چرا نتایج جستجوی شما در موتورهای جستجو همیشه به یک شکل نیست؟ یا چرا برخی از سیستمهای تشخیص چهره، افراد با رنگ پوستهای مختلف را به درستی تشخیص نمیدهند؟ پاسخ این پرسشها را میتوان در وجود بایاس در الگوریتمهای هوش مصنوعی جستجو کرد. اما بایاس هوش مصنوعی دقیقاً چیست و چگونه در مدلهای یادگیری ماشین رخ میدهد؟ چه عواملی باعث ایجاد بایاس میشوند و چگونه میتوان از آن جلوگیری کرد؟ در این مقاله، به بررسی انواع بایاس، تفاوت آن با واریانس، مراحل ایجاد بایاس در چرخه توسعه یادگیری ماشین و راهکارهای مقابله با آن خواهیم پرداخت.

در مقاله حاضر از هامیا ژورنال، شما را با دنیای پیچیده بایاس هوش مصنوعی آشنا خواهیم کرد. ابتدا به بررسی انواع مختلف بایاس در یادگیری ماشین و تفاوت آن با مفهوم واریانس خواهیم پرداخت. سپس، به صورت مرحله به مرحله، چگونگی ایجاد بایاس در هر مرحله از چرخه توسعه یادگیری ماشین را بررسی خواهیم کرد. در ادامه، راهکارهای مختلفی برای کاهش و جلوگیری از بایاس در مدلهای هوش مصنوعی ارائه خواهیم داد. در نهایت، به تاریخچه بایاس در یادگیری ماشین و چالشهایی که در این زمینه وجود دارد، خواهیم پرداخت. با همراهی ما، میتوانید درک عمیقتری از این مسئله مهم در حوزه هوش مصنوعی پیدا کنید و به عنوان یک کاربر یا توسعهدهنده هوش مصنوعی، آگاهانهتر عمل کنید.
فهرست مطالب
بایاس هوش مصنوعی چیست؟
هنگامی که الگوریتمهای یادگیری ماشین آموزش میبینند، گاهی اوقات به دلیل فرضهای نادرست یا دادههای آموزشی ناقص، نتایج آنها به طور سیستماتیک مغرضانه میشود. این پدیده را “بایاس یادگیری ماشین” یا “بایاس الگوریتم” یا “بایاس هوش مصنوعی” مینامیم. به عبارت دیگر، الگوریتمها ممکن است به جای یادگیری الگوهای واقعی از دادهها، الگوهای نادرست و مغرضانهای را یاد بگیرند که منجر به تصمیمگیریهای ناعادلانه میشود.
همانطور که میدانیم، یادگیری ماشین زیرمجموعهای از هوش مصنوعی است و عملکرد آن به شدت به کیفیت و کمیت دادههایی که با آنها آموزش میبیند وابسته است. اگر دادههای آموزشی ناقص، مغرضانه یا دارای خطا باشند، مدل یادگیری ماشین نیز نتایج مغرضانهای تولید خواهد کرد. این مفهوم شبیه به این ضربالمثل در حوزه علوم کامپیوتر و مدلهای زبانی بزرگ است که میگوید “اگر به مدلی زباله وارد شود، زباله نیز خارج خواهد شد”. به عبارت دیگر، اگر به یک مدل اطلاعات نادرست بدهیم، نمیتوانیم انتظار داشته باشیم که نتایج دقیق و عادلانهای تولید کند.
بایاس در یادگیری ماشین اغلب ریشه در تصمیمات و انتخابهای انسان دارد. افرادی که سیستمهای یادگیری ماشین را طراحی و آموزش میدهند، ممکن است ناخواسته تعصبات و باورهای شخصی خود را به مدل منتقل کنند. همچنین، ممکن است از دادههای آموزشی استفاده کنند که نماینده خوبی از جامعه نیستند و گروههای خاصی را نادیده میگیرند. به عنوان مثال، اگر یک سیستم تشخیص چهره عمدتاً بر روی تصاویر افراد سفیدپوست آموزش ببیند، ممکن است در تشخیص چهره افراد با رنگ پوستهای دیگر دچار مشکل شود.
تعصبات و باورهای نادرست انسانها میتوانند به طرق مختلف بر الگوریتمهای یادگیری ماشین تأثیر بگذارند. به عنوان مثال، اگر یک سیستم توصیهگر بر اساس جنسیت یا سن کاربران، پیشنهاداتی را ارائه دهد، این امر ممکن است به تقویت کلیشههای جنسیتی منجر شود. یا اگر یک سیستم استخدام بر اساس سابقه کاری افراد تصمیمگیری کند، ممکن است افرادی را که تجربه کاری متفاوتی دارند، مورد تبعیض قرار دهد. اینها تنها چند نمونه از چگونگی تأثیرگذاری تعصبات انسانی بر سیستمهای هوش مصنوعی هستند.
اگرچه اغلب اوقات، این سوگیریها به صورت ناخواسته وارد سیستمهای یادگیری ماشین میشوند، اما عواقب ناشی از آنها میتواند بسیار جدی باشد. برای مثال، سیستمهای توصیهگر مبتنی بر الگوریتمهای یادگیری ماشین ممکن است محصولات یا خدماتی را به کاربران پیشنهاد دهند که به دلیل سوگیریهای موجود در دادههای آموزشی، با علایق و نیازهای واقعی آنها همخوانی نداشته باشد. در حوزه استخدام، الگوریتمهایی که برای غربالگری رزومهها استفاده میشوند ممکن است به دلیل وجود بایاسهای نژادی یا جنسیتی، فرصتهای شغلی را از افراد مستعد سلب کنند. در حوزه عدالت کیفری، سیستمهای پیشبینی جرم ممکن است بر اساس دادههای تاریخی که خود حاوی سوگیریهای نژادی هستند، افراد بیگناه را به اشتباه مجرم بدانند. به طور کلی، بایاس در سیستمهای یادگیری ماشین میتواند منجر به تبعیض، کاهش اعتماد عمومی و حتی ایجاد خسارات مالی شود.
برای مقابله با مشکل بایاس در مدلهای یادگیری ماشین، لازم است اقدامات پیشگیرانهای صورت گیرد. در مرحله اول، باید به دقت دادههایی که برای آموزش این مدلها استفاده میشوند، بررسی شوند. این دادهها باید نماینده طیف گستردهای از افراد با ویژگیهای مختلف باشند تا از بروز سوگیریهای سیستماتیک جلوگیری شود. به عنوان مثال، اگر یک سیستم تشخیص چهره عمدتاً بر روی تصاویر افراد سفیدپوست آموزش ببیند، ممکن است در تشخیص چهره افراد با رنگ پوستهای دیگر دچار مشکل شود. در مرحله بعد، دانشمندان داده باید از الگوریتمها و تکنیکهایی استفاده کنند که به حداقلسازی سوگیری کمک میکنند. همچنین، تصمیمگیرندگان باید پیش از استقرار سیستمهای یادگیری ماشین در محیطهای واقعی، به دقت آنها را ارزیابی کنند تا از ایجاد آسیبهای احتمالی جلوگیری شود.
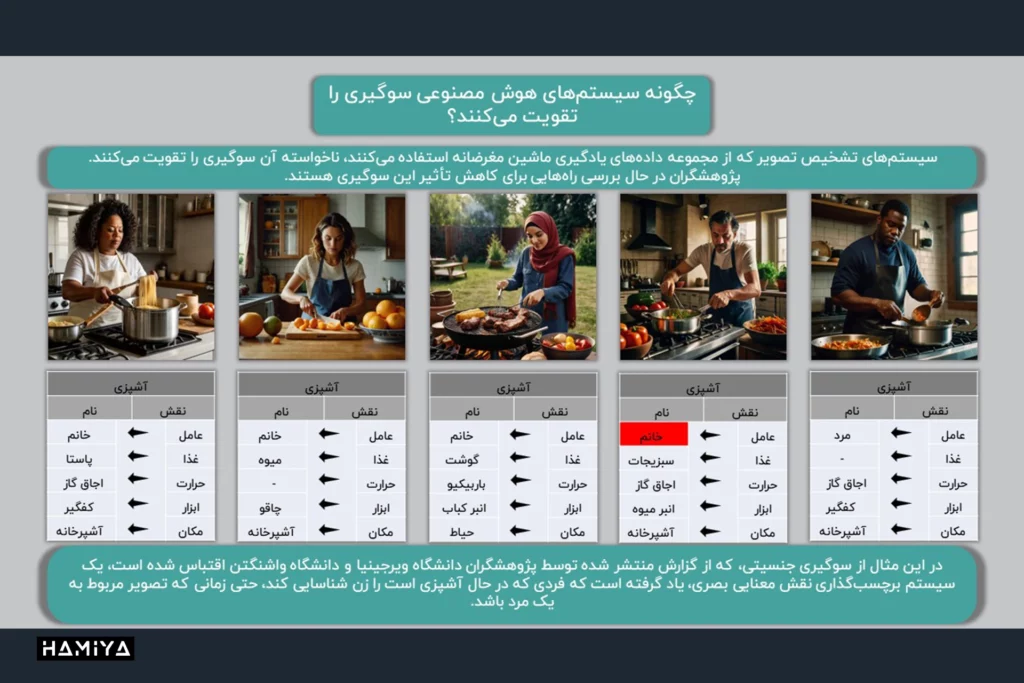
انواع بایاس در یادگیری ماشین
بایاس در سیستمهای یادگیری ماشین (ML) میتواند از منابع مختلفی نشأت بگیرد. به طور کلی، میتوان انواع مختلفی از بایاس را شناسایی کرد که هر یک به شیوهای خاص بر عملکرد و نتایج مدل تأثیر میگذارند. در ادامه، به بررسی برخی از رایجترین انواع بایاس در سیستمهای ML میپردازیم.
- بایاس الگوریتمی. بایاس الگوریتمی زمانی رخ میدهد که خود الگوریتم به گونهای طراحی شده باشد که نتایج مغرضانهای تولید کند. این نوع بایاس ممکن است ناشی از خطاهای برنامهنویسی، فرضهای نادرست در مورد دادهها یا محدودیتهای ذاتی الگوریتم باشد. برای مثال، اگر یک الگوریتم طبقهبندی به گونهای طراحی شده باشد که همیشه یک کلاس خاص را به عنوان خروجی انتخاب کند، صرف نظر از ویژگیهای ورودی، این الگوریتم به طور ذاتی دارای بایاس است.
- بایاس خودکارسازی. این نوع بایاس به اعتماد بیش از حد به سیستمهای خودکار مرتبط است. گاهی اوقات، ما به دلیل خودکار بودن یک سیستم، به نتایج آن اعتماد بیشتری میکنیم، حتی اگر این نتایج دقیق نباشند. این پدیده میتواند منجر به تقویت تصمیمات نادرست و تقویت سوگیریهای موجود شود. یکی از مثالهای بارز بایاس خودکارسازی در حوزه فناوری اطلاعات، اتکا بیش از حد به سیستمهای ناوبری خودکار مانند سیستم موقعیتیابی جهانی (GPS) است. این پدیده زمانی رخ میدهد که کاربران به جای بهرهگیری از قضاوت شخصی و شناخت محیط اطراف، به طور کامل به راهنماییهای ارائه شده توسط این سیستمها اعتماد میکنند. به عنوان مثال، هنگام استفاده از دستگاههای ناوبری در خودرو، کاربران ممکن است بدون توجه به علائم راهنمایی و رانندگی یا شرایط محیطی، صرفاً از مسیر پیشنهادی دستگاه پیروی کنند. حتی در مواردی که مسیر پیشنهادی به دلیل بروز تغییرات ناگهانی در ترافیک یا شرایط جوی نامناسب، بهینه نباشد، کاربران ممکن است به دلیل اعتماد بیش از حد به سیستم، از ارزیابی مجدد مسیر خودداری کنند.
- بایاس نمونه. بایاس نمونه زمانی رخ میدهد که دادههای آموزشی مورد استفاده برای آموزش مدل، نماینده کافی از جامعه هدف نباشند. این عدم نمایندگی میتواند به دلایل مختلفی از جمله کمبود داده، نمونهگیری نادرست یا تعصب در جمعآوری دادهها رخ دهد. به عنوان مثال، استفاده از دادههای آموزشی که فقط شامل معلمان زن است، سیستم را آموزش میدهد تا نتیجهگیری کند که همه معلمان زن هستند.
- بایاس تعصب. بایاس تعصب به انعکاس تعصبات و کلیشههای موجود در جامعه در دادههای آموزشی اشاره دارد. این تعصبات میتوانند در قالب جنسیت، نژاد، قومیت، سن و سایر ویژگیهای اجتماعی باشند. برای مثال، تصور کنید میخواهیم به یک کامپیوتر یاد دهیم که چه کسی میتواند یک پزشک خوبی باشد. اگر به این کامپیوتر فقط اطلاعاتی بدهیم که نشان دهد همه پزشکان مرد هستند و همه پرستاران زن، چه اتفاقی میافتد؟ کامپیوتر یاد میگیرد که این یک قانون کلی است و تصور دیگری نخواهد کرد. این همان چیزی است که ما به آن “بایاس تعصب” میگوییم.
- بایاس ضمنی. بایاس ضمنی به باورها و تعصبات ناخودآگاه طراحان و توسعهدهندگان سیستمهای ML اشاره دارد. این باورها و تعصبات میتوانند به طور ناخواسته در فرآیند طراحی و توسعه مدلها وارد شوند و بر نتایج نهایی تأثیر بگذارند. برای مثال، اگر یک تیم توسعهدهنده عمدتاً متشکل از افراد با پیشینه فرهنگی خاصی باشد، ممکن است مدلهایی ایجاد کنند که برای سایر فرهنگها مناسب نباشند. مثلا تصور کنید یک تیم توسعهدهنده قصد دارند سیستمی برای تشخیص تصاویر حیوانات طراحی کنند. اگر اعضای این تیم عمدتاً در محیطهای شهری بزرگ زندگی کرده باشند و با حیوانات اهلی بیشتر آشنا باشند، ممکن است مدل آنها تنها توانایی شناسایی حیوانات خانگی مانند سگ، گربه و پرندگان را داشته باشد. در این حالت، بایاس ضمنی ناشی از تجربیات شخصی اعضای تیم، باعث میشود که مدل در تشخیص حیوانات وحشی عملکرد ضعیفی داشته باشد.
- بایاس انتساب گروهی. این نوع بایاس زمانی رخ میدهد که ویژگیهای یک فرد یا گروه کوچک به اشتباه به کل یک گروه تعمیم داده شود. به عبارت دیگر، تفاوتهای فردی نادیده گرفته شده و همه افراد یک گروه با یک قالب کلی ارزیابی میشوند. مثالهایی از این نوع بایاس میتواند مواردی مانند مثالهای زیر باشند.
- ورزشکاران: تصور کنید یک ورزشکار حرفهای مرتکب اشتباهی شود. ممکن است بعد از این اتفاق، همه افراد آن رشته ورزشی را بیانضباط و غیرقابل اعتماد بدانیم. در حالی که همه ورزشکاران یکسان نیستند و رفتار یک نفر نباید به کل یک گروه تعمیم داده شود.
- دانشآموزان: اگر یک دانشآموز در کلاس مزاحمت ایجاد کند، ممکن است معلم تصور کند که همه دانشآموزان آن کلاس بیانضباط هستند. در حالی که این احتمال وجود دارد که فقط آن دانشآموز خاص مشکلساز باشد.
- ملیتها: گاهی اوقات بر اساس رفتار یک فرد از یک ملیت خاص، تصوری کلی درباره همه افراد آن ملیت ایجاد میشود. مثلاً ممکن است بگوییم “همه افراد از کشور X بیادب هستند”، در حالی که این تصور بر اساس یک تعمیم نادرست است.
- بایاس اندازهگیری. بایاس اندازهگیری به خطاهایی اشاره دارد که در فرایند جمعآوری و اندازهگیری دادهها رخ میدهند. این خطاها میتوانند ناشی از ابزارهای اندازهگیری نادرست، روشهای جمعآوری دادههای ناکارآمد یا حتی تأثیر مشاهدهگر بر افراد مورد مطالعه باشند. یکی از رایجترین نمونههای بایاس اندازهگیری در حوزه علوم اجتماعی، نظرسنجیها هستند. طراحی نادرست سؤالات در یک نظرسنجی میتواند به شدت بر نتایج آن تأثیر گذاشته و منجر به ایجاد بایاس شود. این پدیده زمانی رخ میدهد که شیوهی طرح سؤال یا گزینههای پاسخ به گونهای باشد که پاسخدهندگان را به سمت انتخاب خاصی سوق دهد. به عنوان مثال، در یک نظرسنجی درباره سیاستهای اقتصادی دولت، اگر سؤالات به گونهای طرح شوند که جنبههای منفی یک سیاست خاص را برجسته کرده و جنبههای مثبت آن را نادیده بگیرند، احتمالاً پاسخدهندگان تمایل بیشتری به ابراز مخالفت با آن سیاست خواهند داشت. این در حالی است که ممکن است با طرح سؤالاتی که به طور عادلانهتری به همه جوانب یک موضوع میپردازند، نتایج متفاوتی حاصل شود.
- بایاس حذف یا گزارشدهی. این نوع بایاس زمانی رخ میدهد که بخش مهمی از دادهها به دلایل مختلف از تحلیل حذف شوند. این حذف میتواند عمدی یا غیرعمدی باشد و باعث ایجاد نتایج مغرضانه شود. به عنوان مثال، در یک کارآزمایی بالینی برای ارزیابی اثربخشی یک داروی جدید، ممکن است برخی از شرکتکنندگان به دلایل مختلفی مانند عوارض جانبی شدید، عدم مشاهده بهبود، یا دلایل شخصی، مطالعه را ترک کنند. اگر تنها دادههای شرکتکنندگانی که تا پایان مطالعه باقی ماندهاند مورد تحلیل قرار گیرد، ممکن است تصویری نادرست از اثربخشی دارو ارائه شود. این امر به این دلیل رخ میدهد که شرکتکنندگانی که مطالعه را ترک میکنند، ممکن است ویژگیهای متفاوتی نسبت به کسانی که به مطالعه ادامه میدهند داشته باشند. برای مثال، بیمارانی که دارویی برای آنها موثر نیست یا عوارض جانبی شدیدی را تجربه میکنند، احتمال بیشتری دارد که مطالعه را ترک کنند. در نتیجه، اگر این بیماران از تحلیل حذف شوند، ممکن است دارو موثرتر از آنچه که در واقع هست به نظر برسد.
- بایاس انتخاب. بایاس انتخاب به مشکلات مرتبط با نمونهگیری اشاره دارد. زمانی که نمونهای که برای آموزش مدل انتخاب میشود، نماینده کافی از جمعیت مورد مطالعه نباشد، این نوع بایاس رخ میدهد. به عنوان مثال، اگر در یک نظرسنجی درباره استفاده از اینترنت، تنها از افرادی که به اینترنت دسترسی دارند پرسش شود، نتایج به دست آمده ممکن است نماینده خوبی از کل جمعیت نباشد.
- بایاس یادآوری. بایاس یادآوری به خطاهایی اشاره دارد که در فرآیند برچسبگذاری دادهها رخ میدهند. این خطاها میتوانند ناشی از حافظه ناقص افراد، تفسیرهای متفاوت از دادهها یا عوامل روانشناختی دیگر باشند. یکی از مصادیق بارز بایاس یادآوری در حوزه روانشناسی شناختی، فرآیند یادآوری اطلاعات در آزمونها و ارزیابیها است. هنگامی که فردی پس از شرکت در یک آزمون، خصوصاً آزمونهای با اهمیت بالا، تلاش میکند محتوای سوالات را به یاد آورد، ممکن است دچار خطاهای شناختی شود. عوامل متعددی میتوانند بر دقت یادآوری تأثیر بگذارند. یکی از مهمترین این عوامل، فشار روانی ناشی از اهمیت آزمون است. استرس ناشی از آزمون میتواند بر عملکرد حافظه کوتاهمدت و بلندمدت تأثیر گذاشته و منجر به فراموشی جزئیات مهم یا تحریف آنها شود. همچنین، تداخل اطلاعات جدید با اطلاعات قدیمی نیز میتواند بر دقت یادآوری تأثیرگذار باشد. به عنوان مثال، مکالمات و فعالیتهای انجام شده پس از آزمون ممکن است بر یادآوری محتوای آزمون تأثیر گذاشته و منجر به ایجاد خاطرات کاذب شوند. علاوه بر این، انتظارات فردی نیز میتواند بر فرآیند یادآوری تأثیر بگذارد. فرد ممکن است بر اساس انتظارات خود از آزمون، اطلاعات را به گونهای بازسازی کند که با این انتظارات همخوانی داشته باشد. به عنوان مثال، اگر فردی انتظار داشته باشد که سؤالات آزمون بیشتر بر روی یک بخش خاص از مطالب متمرکز باشد، ممکن است به اشتباه به یاد آورد که تعداد بیشتری از سؤالات مربوط به آن بخش بوده است.
بایاس در مقابل واریانس
بیشتر بدانید
واریانس: پراکندگی اعداد را نشان میدهد.
فرض کنید میخواهیم عملکرد دو تیم فوتبال را در طول یک فصل بررسی کنیم. تیم اول در تمام بازیها تقریباً امتیاز یکسانی کسب کرده است، اما تیم دوم در برخی بازیها امتیاز بسیار بالا و در برخی دیگر امتیاز بسیار پایینی کسب کرده است. در این حالت، واریانس امتیازات تیم دوم بسیار بیشتر از تیم اول است. به عبارت سادهتر، نتایج تیم دوم پراکندهتر و متغیرتر از تیم اول است.
واریانس به ما کمک میکند تا بفهمیم که دادههای ما چقدر از هم دور هستند. در مثال تیمهای فوتبال، واریانس بالا نشان میدهد که نتایج تیم دوم قابل پیشبینی نیست و عملکرد آنها در هر بازی میتواند بسیار متفاوت باشد. در مقابل، واریانس پایین نشان میدهد که نتایج تیم اول پایدارتر است و میتوان انتظار داشت که آنها در بازیهای آینده نیز عملکرد مشابهی داشته باشند.
در توسعه و استفاده از مدلهای یادگیری ماشین، علاوه بر توجه به مسئله بایاس، باید به عامل دیگری به نام واریانس نیز توجه شود. این دو مفهوم به طور مستقیم بر دقت و قابلیت تعمیمپذیری مدل تأثیر میگذارند. هدف اصلی در طراحی مدلهای یادگیری ماشین، یافتن تعادلی مناسب بین این دو عامل است تا بتوان به نتایج دقیق و قابل اعتمادی دست یافت.
واریانس در واقع بیانگر میزان حساسیت مدل به تغییرات کوچک در دادههای آموزشی است. به عبارت دیگر، اگر دادههای آموزشی کمی تغییر کنند، آیا مدل نیز تغییرات قابل توجهی خواهد داشت؟ در حالی که بایاس به دلیل فرضهای نادرست در مدل ایجاد میشود، واریانس ناشی از نوسانات تصادفی در دادهها است. این نوسانات ممکن است ناشی از خطاهای اندازهگیری، نمونهگیری نادرست یا عوامل تصادفی دیگر باشند.
واریانس بالا نشان میدهد که مدل به شدت به دادههای آموزشی وابسته است و ممکن است در مواجهه با دادههای جدید عملکرد ضعیفی از خود نشان دهد. این پدیده را اصطلاحاً “بیشبرازش” مینامند. در مقابل، اگر واریانس بسیار پایین باشد، مدل ممکن است به اندازه کافی پیچیده نباشد تا الگوهای موجود در دادهها را یاد بگیرد و در نتیجه عملکرد آن ضعیف خواهد بود. این پدیده را اصطلاحاً “کمبرازش” مینامند. بنابراین، هدف ما یافتن و یا ساختن مدلی است که هم بایاس کم و هم واریانس کمی داشته باشد.
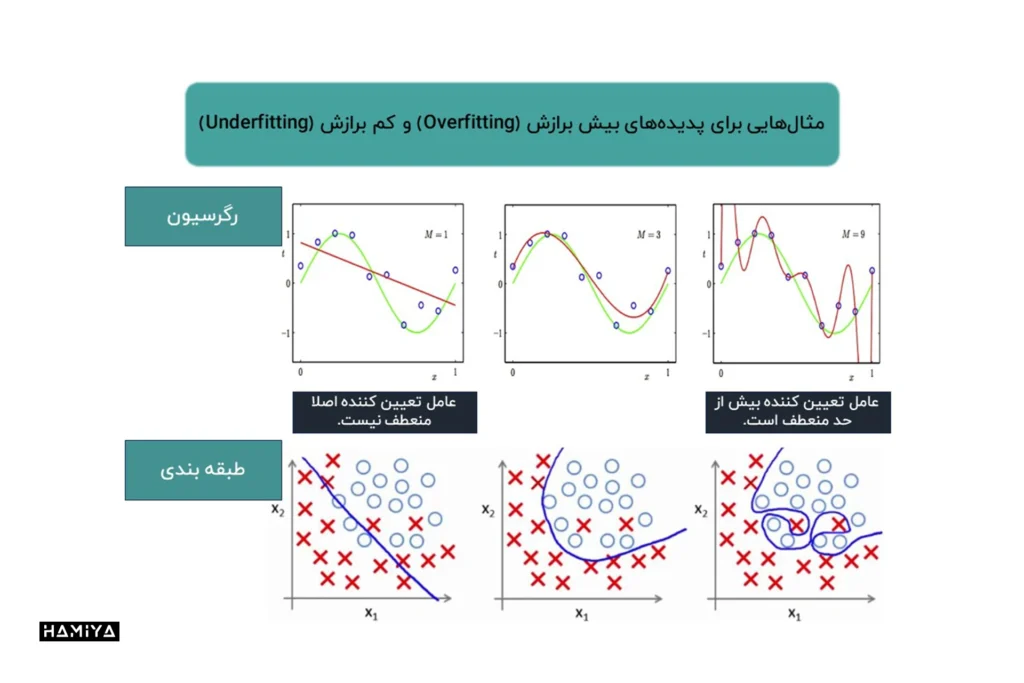
برای کاهش واریانس در مدلهای یادگیری ماشین، میتوان از روشهای مختلفی استفاده کرد. برخی از این روشها عبارتند از: اعتبارسنجی متقابل دادهها، کاهش ویژگیها، استفاده از تکنیکهای منظمسازی، سادهسازی مدل و غیره
بایاس و واریانس دو مفهوم کلیدی در یادگیری ماشین هستند که هر دو بر دقت مدل تأثیر میگذارند. با وجود تفاوتهایشان، این دو مفهوم به شدت به هم مرتبط هستند. گاهی اوقات، کاهش یکی از آنها میتواند به افزایش دیگری منجر شود. به عنوان مثال، اگر مدل ما بیش از حد پیچیده باشد (واریانس بالا)، ممکن است به خوبی با دادههای جدید تعمیم پیدا نکند، اما ممکن است بتواند دادههای آموزشی را به خوبی مدل کند (بایاس کم). از سوی دیگر، اگر مدل بسیار ساده باشد (بایاس بالا)، ممکن است نتواند الگوهای پیچیده در دادهها را تشخیص دهد، اما در مقابل، به تغییرات کوچک در دادهها حساس نخواهد بود (واریانس کم). بنابراین، هدف اصلی در طراحی مدلهای یادگیری ماشین، یافتن تعادل مناسب بین بایاس و واریانس است. نوع الگوریتمی که انتخاب میکنیم، نقش مهمی در تعیین این تعادل ایفا میکند. در این قسمت از مقاله، چندین مثال ذکر شده است:
- الگوریتمهای کیسهبندی (Bagging algorithms) میتوانند بایاس کم و واریانس بالا داشته باشند.
- الگوریتمهای درخت تصمیم میتوانند بایاس کم و واریانس بالا داشته باشند. این الگوریتمها به دلیل قابلیت یادگیری الگوهای بسیار پیچیده، اغلب واریانس بالایی دارند. این بدان معناست که درختهای تصمیم ممکن است به تغییرات کوچک در دادههای آموزشی بسیار حساس باشند و در نتیجه، بر روی دادههای جدید عملکرد خوبی نداشته باشند.
- الگوریتمهای رگرسیون خطی میتوانند بایاس بالا و واریانس پایین داشته باشند. رگرسیون خطی یک مدل سادهای است که فرض میکند رابطه بین متغیرهای مستقل و وابسته خطی است. این فرض سادهسازی میتواند منجر به بایاس بالا شود، به خصوص اگر رابطه بین متغیرها غیرخطی باشد. با این حال، مدلهای رگرسیون خطی معمولاً واریانس پایینی دارند، زیرا به تغییرات کوچک در دادهها حساس نیستند.
- الگوریتمهای جنگل تصادفی میتوانند بایاس کم و واریانس بالا داشته باشند.
در نهایت، هدف اصلی در یادگیری ماشین یافتن مدلی است که بتواند هم الگوهای پیچیده در دادهها را تشخیص دهد (بایاس کم) و هم در برابر تغییرات کوچک در دادهها مقاوم باشد (واریانس کم). انتخاب الگوریتم مناسب، تنظیم پارامترهای مدل و استفاده از تکنیکهای مختلف مانند اعتبارسنجی متقاطع، همگی به ما کمک میکنند تا به این هدف دست پیدا کنیم.

بایاس در چرخه حیات یادگیری ماشین
بایاس، به عنوان یک خطای سیستماتیک، در تمام مراحل توسعه و کاربرد سیستمهای یادگیری ماشین میتواند رخ دهد. این خطاها اغلب ریشه در دادهها، الگوریتمها یا تصمیمگیریهای انسانی دارند. برای ایجاد سیستمهای هوش مصنوعی عادلانه و قابل اعتماد، شناخت دقیق نقاطی که بایاس میتواند وارد طول کانال اطلاعات ML شود توسط متخصصان هوش مصنوعی ضروری است. این نقاط عبارتند از:
بایاس هوش مصنوعی در مرحله جمعآوری و آمادهسازی دادهها
دادهها به عنوان سوخت سیستمهای یادگیری ماشین، نقش بسیار مهمی دارند. هرگونه نقص یا سوگیری در دادهها میتواند به طور مستقیم بر عملکرد مدل تأثیر بگذارد. برخی از منابع رایج بایاس در این مرحله عبارتند از:
- نمونهگیری نادرست: اگر دادهها به صورت تصادفی یا نماینده از جمعیت مورد مطالعه انتخاب نشوند، مدل ممکن است نتایج مغرضانهای تولید کند.
- خطاهای اندازهگیری: خطاهای اندازهگیری در دادهها میتواند باعث ایجاد نویز و کاهش دقت مدل شود.
- پیشپردازش دادهها: روشهای پیشپردازش دادهها مانند حذف دادههای پرت یا استانداردسازی ویژگیها نیز میتوانند به طور ناخواسته باعث ایجاد بایاس شوند.
بایاس هوش مصنوعی در مرحله انتخاب مدل
انتخاب مدل مناسب برای یک مسئله خاص نیز میتواند بر میزان بایاس تأثیرگذار باشد. برخی از الگوریتمها به دلیل ساختار یا فرضهای درونی خود، مستعد ایجاد بایاس هستند. همچنین، انتخاب ویژگیهای نامناسب یا طراحی نادرست معماری مدل میتواند به تقویت بایاس موجود کمک کند.
بایاس هوش مصنوعی در مرحله توسعه
- داده های آموزشی: داده های آموزشی ناکافی یا مغرضانه می توانند منجر به مدل هایی شوند که بایاس های موجود را تقویت می کنند.
- پیاده سازی الگوریتم: خطاها در پیاده سازی الگوریتم می توانند بایاس را تقویت کنند.
- آموزش مدل: روش های آموزشی ضعیف مانند بازخورد انسانی نادرست و اعتبارسنجی ناکافی با مجموعه داده آزمایشی کوچک یا ناکافی، همگی تأثیر منفی بر مدل خواهند داشت.
بایاس هوش مصنوعی در مرحله عملیاتی
حتی پس از آموزش و استقرار مدل، امکان ایجاد بایاس وجود دارد. بازخوردهای انسانی که بر اساس تعصبات شخصی ارائه میشوند، میتوانند به تقویت بایاسهای موجود در مدل کمک کنند. همچنین، تفسیر نتایج مدل توسط افراد نیز میتواند تحت تأثیر تعصبات آنها قرار گیرد.
با درک دقیق منابع مختلف بایاس در چرخه حیات یادگیری ماشین، میتوان اقدامات پیشگیرانهای برای کاهش این خطاها انجام داد. این اقدامات شامل بهبود کیفیت دادهها، انتخاب دقیق الگوریتمها، ارزیابی جامع مدلها و طراحی سیستمهای بازخورد شفاف و عادلانه میشود.
چگونه از بایاس هوش مصنوعی جلوگیری کنیم؟
آگاهی از وجود بایاس در سیستمهای یادگیری ماشین و اقدامات پیشگیرانه برای مقابله با آن، از اهمیت بالایی برخوردار است. سازمانهایی که به این موضوع توجه دارند میتوانند با اجرای روشهای مناسب، از بروز بسیاری از مشکلات ناشی از بایاس جلوگیری کنند. مراحل زیر، گامهای اساسی برای مقابله با بایاس در یادگیری ماشین هستند:
1. انتخاب دقیق دادههای آموزشی
دادهها به عنوان پایه و اساس هر سیستم یادگیری ماشین، نقش تعیینکنندهای در کیفیت و عادلانه بودن نتایج دارند. برای جلوگیری از بروز بایاس، لازم است دادههای آموزشی:
- نماینده جمعیت هدف باشند: دادهها باید تنوع کافی داشته باشند تا بتوانند تمام گروههای مورد نظر را پوشش دهند.
- حجم کافی داشته باشند: حجم دادههای آموزشی باید به اندازهای باشد که مدل بتواند الگوهای پیچیده را یاد بگیرد.
- از کیفیت بالایی برخوردار باشند: دادهها باید عاری از خطا، نویز و ناسازگاری باشند.
- با دقت برچسبگذاری شوند: برچسبگذاری دادهها باید توسط افراد متخصص و با استفاده از معیارهای دقیق انجام شود.
2. تست و اعتبارسنجی مداوم
پس از آموزش مدل، لازم است آن را به دقت مورد ارزیابی قرار داد تا از عملکرد صحیح و عادلانه آن اطمینان حاصل شود. روشهای مختلفی مانند اعتبارسنجی متقاطع و آزمونهای آماری برای بررسی عملکرد مدل در برابر دادههای جدید استفاده میشوند. هدف از این مرحله، شناسایی و رفع هرگونه بایاس موجود در مدل است.
3. نظارت بر مدل در طول زمان
بایاس ممکن است حتی پس از استقرار مدل نیز ایجاد شود. به همین دلیل، لازم است مدلها به طور مداوم تحت نظارت قرار گیرند تا از عدم تغییر عملکرد آنها اطمینان حاصل شود. این کار به ویژه در مواردی که دادههای ورودی به مدل به طور مداوم تغییر میکنند، اهمیت بیشتری پیدا میکند.
4. استفاده از ابزارهای تخصصی
ابزارهای مختلفی برای شناسایی و کاهش بایاس در سیستمهای یادگیری ماشین توسعه یافتهاند. این ابزارها میتوانند به متخصصان کمک کنند تا مدلهای خود را به صورت دقیقتری بررسی و ارزیابی کنند. برخی از این ابزارها عبارتند از:
- What-If Tool: ابزاری تعاملی برای بررسی رفتار مدلها و شناسایی الگوهای بایاس.
- AI Fairness 360: یک جعبه ابزار متنباز که شامل مجموعهای از متریکها و الگوریتمها برای ارزیابی و کاهش بایاس در سیستمهای یادگیری ماشین است.
5. برای کاهش بایاس در مدلهای یادگیری ماشین، باید دادههای آموزشی به گونهای جمعآوری شوند که تنوع و گوناگونی نظرات و دیدگاهها را در خود داشته باشد. به عبارت دیگر، هر داده میتواند دارای چندین برچسب یا طبقهبندی بالقوه باشد. این رویکرد باعث میشود مدل یاد بگیرد که با پیچیدگیهای دنیای واقعی بهتر کنار بیاید و از ایجاد تعصبات یکجانبه جلوگیری کند.
6. دادههای آموزشی به عنوان پایه و اساس هر مدل یادگیری ماشین، نقش بسیار مهمی در عملکرد و دقت آن دارند. بنابراین، درک عمیق از دادهها و توجه به کیفیت آنها از اهمیت بالایی برخوردار است. برچسبگذاری دقیق و سازگار دادهها، یکی از مهمترین مراحل در آمادهسازی دادهها برای آموزش مدل است. هرگونه خطا یا نادرستی در برچسبگذاری میتواند به طور مستقیم بر عملکرد مدل و ایجاد بایاس تأثیر بگذارد.

7. مدلهای یادگیری ماشین به عنوان سیستمهای دینامیک، دائماً در حال یادگیری و بهبود هستند. بنابراین، لازم است عملکرد آنها به طور مداوم مورد ارزیابی و پایش قرار گیرد. با دریافت بازخوردهای جدید و بهروزرسانی مداوم مدل، میتوان از ایجاد بایاسهای جدید جلوگیری کرد و عملکرد مدل را بهبود بخشید.
8. یکی از منابع مهم ایجاد بایاس در مدلهای یادگیری ماشین، دخالت انسان در تکمیل دادههای ناقص یا گمشده است. این عمل، که به آن “الحاق (imputation)” گفته میشود، میتواند به دلیل تعصبات شخصی فردی که دادهها را تکمیل میکند، منجر به ایجاد بایاس در مدل شود.
تاریخچه بایاس یادگیری ماشین
مفهوم “بایاس الگوریتمی” نخستین بار توسط تریشان پانچ (Trishan Panch) و هیتر ماتی (Heather Mattie) در دانشگاه هاروارد مطرح شد. اگرچه این مفهوم در دهههای اخیر به طور گستردهای مورد توجه قرار گرفته است، اما ریشههای آن به گذشتههای دورتر برمیگردد. با این حال، پیچیدگی این مسئله و عواقب جدی آن، همچنان چالشهای بزرگی را برای محققان و توسعهدهندگان سیستمهای هوشمند ایجاد میکند.
بایاس الگوریتمی تنها یک مفهوم نظری نیست، بلکه در بسیاری از موارد واقعی و کاربردی، تأثیرات قابل توجهی داشته است. برخی از این موارد، عواقب بسیار جدی و حتی تغییردهنده زندگی افراد داشتهاند.
یکی از مشهورترین مثالهای بایاس الگوریتمی، سیستم COMPAS است که برای پیشبینی احتمال تکرار جرم توسط مجرمان استفاده میشد. این سیستم به طور گسترده در سیستم قضایی برخی ایالتهای کشور آمریکا در اوایل قرن 21 مورد استفاده قرار گرفت تا در تعیین نوع مجازات افراد نقش داشته باشد. با این حال، مطالعات نشان داد که این سیستم به طور سیستماتیک علیه افراد رنگینپوست تعصب نشان میدهد و احتمال بیشتری برای پیشبینی اشتباه مجرم بودن آنها نسبت به افراد سفیدپوست دارد. این مسئله نشان میدهد که چگونه بایاس الگوریتمی میتواند منجر به تبعیض سیستماتیک در سیستم قضایی شود.
مثال دیگری از بایاس الگوریتمی، در شرکت آمازون در سال 2018 رخ داد. آمازون از یک الگوریتم یادگیری ماشینی برای بررسی رزومههای کاری و انتخاب بهترین کارمندها استفاده میکرد. اما این الگوریتم به دلیل آموزش بر روی دادههای تاریخی که حاوی تعصبات جنسیتی بود، به طور ناخودآگاه کاندیداهای زن را رد میکرد. این الگوریتم، کلمات و عبارتهایی را که بیشتر در رزومههای مردان استفاده میشد، به عنوان نشانههای مثبت در نظر میگرفت و در نتیجه، رزومههای زنان را با نمره پایینتری ارزیابی میکرد. این مورد نشان میدهد که چگونه بایاسهای موجود در دادههای آموزشی میتوانند به طور مستقیم بر نتایج الگوریتمها تأثیر بگذارند.
در سال 2018، پژوهشگران دانشگاهی با انجام مطالعات گسترده نشان دادند که سیستمهای تشخیص چهره تجاری موجود، دارای تعصبات جنسیتی و نژادی قابل توجهی هستند. این یافتهها زنگ زنگ خطری جدی برای استفاده از این سیستمها در حوزههای حساس مانند نظارت و اجرای قانون به صدا درآورد.
حوزه پزشکی نیز از تأثیرات مخرب بایاس الگوریتمی در امان نمانده است. مطالعات نشان دادهاند که برخی از سیستمهای هوش مصنوعی که برای تصمیمگیری در مورد درمان بیماران استفاده میشوند، دارای تعصبات نژادی هستند. به عنوان مثال، در سال 2019، یک مطالعه نشان داد که یک سیستم هوش مصنوعی بهکار رفته در چندین بیمارستان، بیماران سیاهپوست را به اشتباه بیمارتر از بیماران سفیدپوست تشخیص داده و در نتیجه، مراقبتهای پزشکی کمتری را برای آنها تجویز میکرد. این مسئله نیز نشان دهندهی تاثیر بایاس الگوریتمی بر نابرابری دسترسی به خدمات بهداشتی بود.
مطالعات اخیر همچنین نشان میدهند که بایاس الگوریتمی در سیستمهای اعتباری نیز نفوذ کرده است. تحقیقات بانک فدرال رزرو فیلادلفیا نشان میدهد که در سالهای 2018 و 2019، حدود 18 درصد از متقاضیان سیاهپوست وام مسکن به دلیل تعصبات موجود در الگوریتمهای تصمیمگیری، با درخواست آنها مخالفت شده است. همچنین، مطالعات دیگر نشان دادهاند که متقاضیان از اقلیتهای نژادی دیگر نیز با احتمال بیشتری با رد درخواست وام مسکن مواجه میشوند. این مسئله نه تنها به نابرابری اقتصادی دامن میزند، بلکه بر فرصتهای اجتماعی و اقتصادی افراد نیز تأثیر میگذارد.
اگر محتوای ما برایتان جذاب بود و چیزی از آن آموختید، لطفاً لحظهای وقت بگذارید و این چند خط را بخوانید:
ما گروهی کوچک و مستقل از دوستداران علم و فناوری هستیم که تنها با حمایتهای شما میتوانیم به راه خود ادامه دهیم. اگر محتوای ما را مفید یافتید و مایلید از ما حمایت کنید، سادهترین و مستقیمترین راه، کمک مالی از طریق لینک دونیت در پایین صفحه است.
اما اگر به هر دلیلی امکان حمایت مالی ندارید، همراهی شما به شکلهای دیگر هم برای ما ارزشمند است. با معرفی ما به دوستانتان، لایک، کامنت یا هر نوع تعامل دیگر، میتوانید در این مسیر کنار ما باشید و یاریمان کنید. ❤️





